10 Open-source free Self-hosted Document Search Engines


When you're using a search engine to find the closest coffee shop, you're probably not thinking about the technology behind it all. But later, you might wonder how did that search engine do that?
How did it sort through the entire internet so quickly and choose the result you saw on the page?
Each search engine uses its software program, but they all work similarly.
They all perform three basic tasks. First, they examine the content they learn about and have permission to see; that's called crawling. Second, they categorize each piece of content; that's called indexing. And, third, they decide which content is most useful to the searchers; that's called ranking.
Document search engines are useful for a large volume of the dataset. Because it is hard to get any useful information from that volume of the dataset, it's necessary to come up with a solution that can help the business needs in the short term as well as the long term.
The primary features for a document search engine
- Searching: Keyword-Based Search, Topic-Based Searching, Semantic Search
2. KeyPhrase Extraction.
3. Text Summarization.
4. Highlight the query result.
5. Document Categorization.
6. Feedback Learning / Query Re-ranking.
Top 10 open-source Document Search Engine
1. Ambar
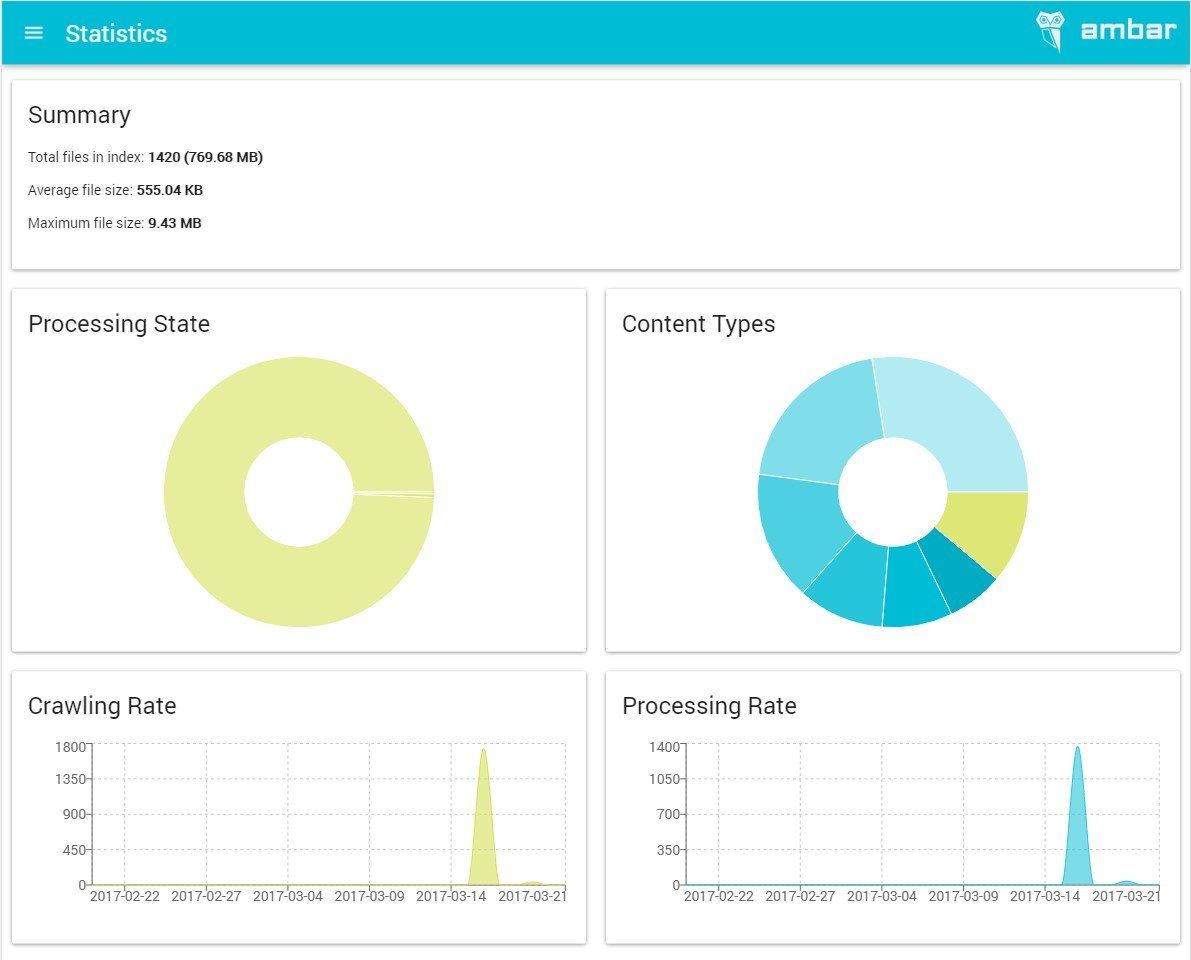
An open-source document search engine as well as a way to implement full-text document search into your workflow. Ambar comes with automated crawling, OCR, tagging, and instant full-text search. Based on open technology similar to JavaScript, Python, CSS.
This document search engine is compatible with all the common file types like ZIP archives, Mail archives (PST), MS Office documents (Word, Excel, PowerPoint, Visio, Publisher), OCR over images, email messages with attachments, Adobe PDF (with OCR), and several others. It is licensed under MIT license.
Features:
- Perform a Google-like search through your documents and images contents
- Tag your documents to easily find what you need
- Ambar supports all popular document formats
- Ambar performs OCR on your images and PDFs
- Easily deploy Ambar with a single docker-compose file
- Use a simple REST API to integrate Ambar into your workflow
GitHub: https://github.com/RD17/ambar
 RD17
RD172. Cider
The Cider document search engine is one of the valuable additions to our list.
The program is written in Java, this content integration framework can store parsed entities into Jena (http://jena.sourceforge.net/) RDF vocabularies and provides a knowledge-based enhanced semantic analysis of content. It is document extraction and retrieval. Moreover, it is released under the LGPL-3.0 license.
GitHub: https://github.com/yacy/cider
yacy3. Open Semantic Search
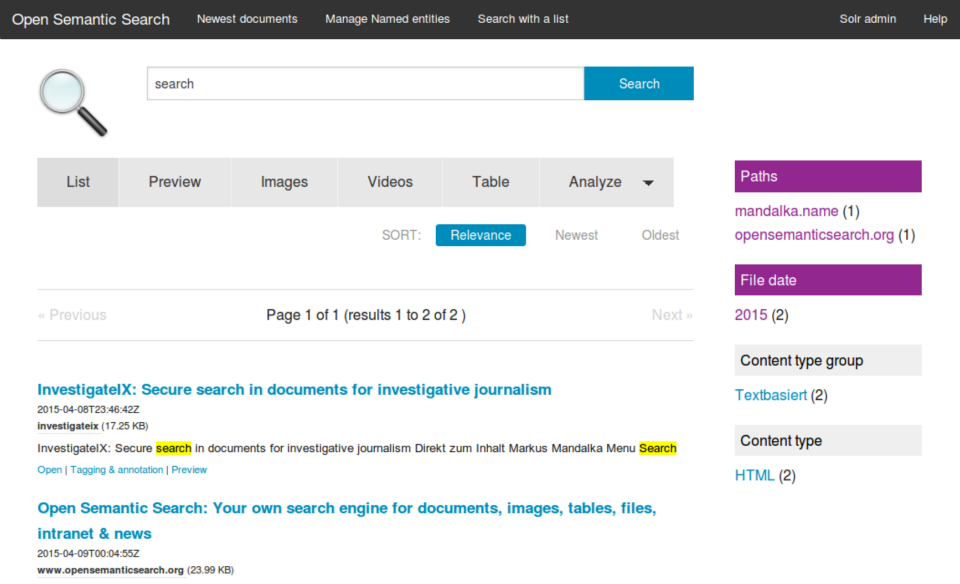
Another Dockerfile, JavaScript-based open-source document search engine; the Open Semantic Search supports different file formats, multiple data sources. The best thing about the open Semantic Search is that it is Free Software for your own Search Engine which is open-source enterprise-search and Open Standards for Linked Data, Semantic Web, and Linked Open Data integration.
Features:
- Full text search
- Thesaurus and Grammar (Semantic search)
- Interactive filters(Faceted search)
- Exploration, browsing, and preview(Exploratory search)
- Collaborative annotation and tagging (Social search and collaborative filtering)
- Data visualization
- Monitoring: Alerts and Watchlists (Newsfeeds)
- Automatic text recognition
GitHub: https://github.com/opensemanticsearch/open-semantic-search
opensemanticsearch4. IResearch search engine
A performance document-oriented search engine library, IResearch is a cross-platform that is written entirely in C++. It is focused on the pluggability of different ranking/similarity models.
This software is provided under the Apache 2.0 Software license.
Features:
- It has a library that is meant to be treated as a standalone index
- Indexed data is treated on a per-version/per-revision basis
- It allows for trivial multithreaded read/write operations on the index
- A database record is represented as an abstraction called a document. A document is actually a collection of indexed/stored fields.
GitHub: https://github.com/iresearch-toolkit/iresearch
iresearch-toolkit5. hOOt

hOOt is a free and Smallest full-text search engine. This software built from scratch using inverted WAH bitmap Roaring bitmap index, highly compact storage, operating in database and document modes.
Features:
- Blazing fast operating speed (see performance test section)
- Incredibly small code size.
- Uses WAH compressed BitArrays to store information.
- Multithreaded implementation, meaning you can query while indexing.
- Highly optimized storage, typically ~60% smaller than lucene.net (the more in the index the greater the difference).
- Tiny size, only 38kb DLL (lucene.net is ~300kb).
GitHub: https://github.com/mgholam/hOOt
mgholam6. Perlin
Perlin is one of the free document search engines build on top of Perlin-core. This software is written on Rust. It is released under an MIT license.
GitHub: https://github.com/CurrySoftware/perlin
CurrySoftware7. MetaFinder
An open-source document search engine, MetaFinder can be easily downloaded for free use. Available on multiple platforms, you will not have to worry about the platform that you are using. The objective is to extract metadata.
MetaFinder is written with Python and licensed under the GPL-3.0 license.
GitHub: https://github.com/Josue87/MetaFinder
Josue878. Search-engine
Search-engine is another highly innovative search engine for document searching that you can opt for.
Search-engine has written in Ruby, Python, JavaScript. It uses PostgreSQL as a database backend.
GitHub: https://github.com/chihsuan/search-engine
chihsuan9. Let's CC

Available in both professional and community editions, the Let's CC is another great free search engine service that you can use. The community edition is distributed under the CCL (Creative Commons License) and it is completely free to download. It is written in PHP.
GitHub: https://github.com/neomparam/letscc
neomparam10. Inteligent Document Finder
Document search engine tool that you can use. Programmed in Python, the software works on the Flask framework. It is licensed under MIT license.
GitHub: https://github.com/Sarthakjain1206/Intelligent_Document_Finder
Sarthakjain1206Conclusion
Such services don’t have to cost huge amounts of money since open-source solutions are available. We reviewed ten common open-source document search engines which are all available for you to choose from.
If you have any additional software you would like to see in this list, then we would love to hear about them in the comments.