Autodistill: The Future of Efficient, AI-Powered Image Recognition


What is Autodistill?
Autodistill is a free and open-source AI project that uses large, slower foundation models to train smaller, faster supervised models, allowing for inference on unlabeled images with no human intervention.
It can be used on personal hardware or via Roboflow's hosted version for cloud-based image labeling. Currently, it supports vision tasks such as object detection and instance segmentation, with potential for future expansion to language models.
 Hazem
Hazem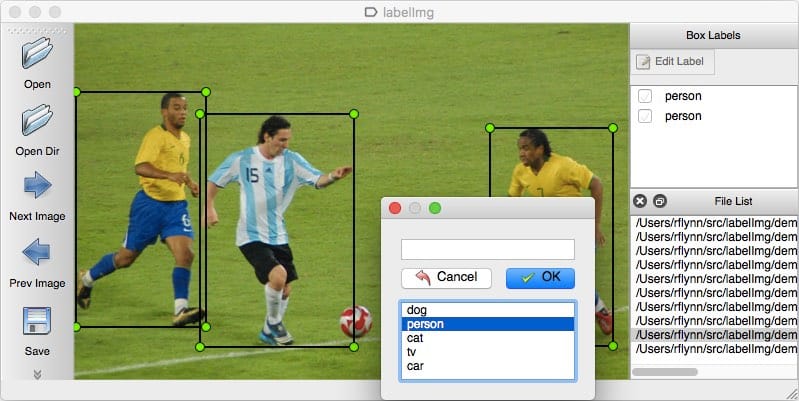
Features
- Pluggable interface to connect models together
- Automatic dataset labeling
- Training of fast supervised models
- Ownership of your model
- Deployment of distilled models to the cloud or the edge
- Built-in object detection
- Dozens of models
- Instance segmentation models
- Classification models
Video
Basic Concepts
To use autodistill, you input unlabeled data into a Base Model which uses an Ontology to label a Dataset that is used to train a Target Model which outputs a Distilled Model fine-tuned to perform a specific Task.
Autodistill defines several basic primitives:
- Task - A Task defines what a Target Model will predict. The Task for each component (Base Model, Ontology, and Target Model) of an
autodistillpipeline must match for them to be compatible with each other. Object Detection and Instance Segmentation are currently supported through thedetectiontask.classificationsupport will be added soon. - Base Model - A Base Model is a large foundation model that knows a lot about a lot. Base models are often multimodal and can perform many tasks. They're large, slow, and expensive. Examples of Base Models are GroundedSAM and GPT-4's upcoming multimodal variant. We use a Base Model (along with unlabeled input data and an Ontology) to create a Dataset.
- Ontology - an Ontology defines how your Base Model is prompted, what your Dataset will describe, and what your Target Model will predict. A simple Ontology is the
CaptionOntologywhich prompts a Base Model with text captions and maps them to class names. Other Ontologies may, for instance, use a CLIP vector or example images instead of a text caption. - Dataset - a Dataset is a set of auto-labeled data that can be used to train a Target Model. It is the output generated by a Base Model.
- Target Model - a Target Model is a supervised model that consumes a Dataset and outputs a distilled model that is ready for deployment. Target Models are usually small, fast, and fine-tuned to perform a specific task very well (but they don't generalize well beyond the information described in their Dataset). Examples of Target Models are YOLOv8 and DETR.
- Distilled Model - a Distilled Model is the final output of the
autodistillprocess; it's a set of weights fine-tuned for your task that can be deployed to get predictions.
License
The autodistill package is licensed under an Apache 2.0. Each Base or Target model plugin may use its own license corresponding with the license of its underlying model.
Resources & Downloads
 autodistillHazem
autodistillHazem