Enhance Document OCR with LLMs: 14 Open-Source Free Tools
OCR Evolution: Adding Language Models to Text Recognition

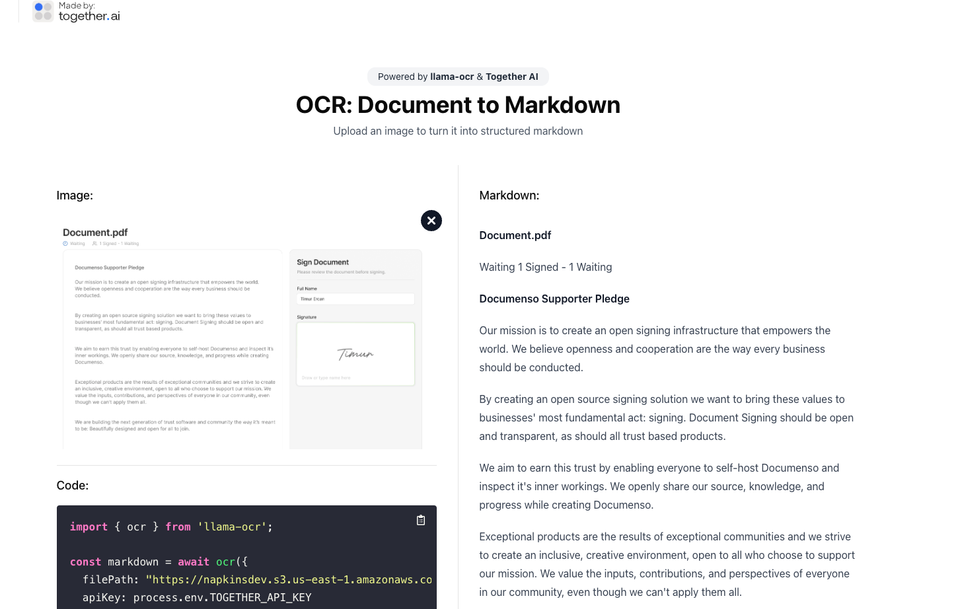
Table of Content
Converting scanned documents to digital text remains challenging, especially for complex materials like research papers, legal documents, and financial records. While standard text recognition works for basic documents, it often fails with tables, equations, and unusual layouts.
New approaches combining traditional scanning with language models offer better solutions for these difficult cases.
Classic Text Recognition: How It Works
Standard text scanning uses several methods:
- Pattern matching against known letter shapes
- Breaking down character features (lines, curves)
- Splitting pages into sections before processing
- Grouping connected pixels to find text blocks
Pros
- Proven reliability for standard documents
- Fast processing
- Works on basic hardware
Cons
- Struggles with complex page layouts
- Can't interpret unclear characters using context
- Poor results from low-quality scans
- Often fails with technical content
Adding Large Language Models (LLMs): The New Approach
Modern systems combine traditional scanning with advanced text processing:
- Initial scan captures text locations
- Language model refines the results
- Software analyzes document structure
- System processes both text and layout together
Advantages
- Better accuracy on complex documents
- Preserves page structure
- Fixes scanning mistakes
- Handles poor quality originals
Drawbacks
- Needs powerful computers
- Higher operating costs
- Slower processing
- Still depends on scan quality
 Hazem Abbas
Hazem Abbas Hazem Abbas
Hazem Abbas
Impact on Document Processing
This shift changes how we handle different materials:
- Context Matters: Language models understand meaning, not just shapes
- Better with Complexity: Handles unusual layouts more effectively
- Right Tool, Right Job: Standard scanning works for simple tasks, language models excel with technical content
Looking Forward
Language model-enhanced scanning marks a significant advance in processing complex documents.
It particularly helps fields needing precise results, like research and healthcare. While requiring more computing power and time, these systems deliver better results for challenging materials.
Organizations should choose based on their needs: standard scanning for basic documents, enhanced systems for complex technical materials requiring high accuracy.
Hazem Abbas
Open-source LLM-based OCR solutions
1- LLM PDF OCR API
llm-pdf-ocr-api is a headless Flask-based web service designed to perform Optical Character Recognition (OCR) on PDF files using machine vision and AI models.
The app is built on PyTorch and Transformers and optimized with NVIDIA CUDA, this API provides two endpoints, one for OCR processing, and one for listing available models. This API is wrapped in a Docker container.
2- BetterOCR
BetterOCR is an open-source OCR solution that combines several OCR engines with LLM to reconstruct the correct output.
It supports several languages and allows developers to define custom context.
3- Surya
Surya is an open-source document OCR toolkit that does:
- OCR in 90+ languages that benchmarks favorably vs cloud services
- Line-level text detection in any language
- Layout detection and analysis (table, image, header, etc detection)
- Reading order detection
- Table recognition (detecting rows/columns)
Surya has been tested with several languages and complex documents and proven to be reliable.
4- docTR

While it does not use LLM as other solutions here, docTR (Document Text Recognition) is an open-source (Apache 2.0 licensed) seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
5- Open-DocLLM
Open-DocLLM is an open-source tool for extracting and answering questions directly from PDF documents using OCR. It processes PDF files, indexes their content, and lets users ask questions to retrieve relevant information.
It’s ideal for searching through large document collections, especially in research or document-heavy environments. The platform is also compatible with various language models, providing flexibility and accuracy in document-based queries.
You can run it locally, using Python or Docker.
6- LLM-Aided OCR Project
The LLM-Aided OCR Project is yet another OCR that uses advanced NLP and large language models (LLMs) to improve OCR accuracy, producing well-formatted, readable documents from raw OCR text. It enhances OCR output quality, making scanned texts more accurate and user-friendly.
Features
- PDF to image conversion
- OCR using Tesseract
- Advanced error correction using LLMs (local or API-based)
- Smart text chunking for efficient processing
- Markdown formatting option
- Header and page number suppression (optional)
- Quality assessment of the final output
- Support for both local LLMs and cloud-based API providers (OpenAI, Anthropic)
- Asynchronous processing for improved performance
- Detailed logging for process tracking and debugging
- GPU acceleration for local LLM inference
 Dicklesworthstone
Dicklesworthstone7- llm-document-ocr
LLM Based OCR and Document Parsing for Node.js. Uses GPT4 and Claude3 for OCR and data extraction.
Features
- Converts PDFs (including multi page PDFs) into PNGs for use with GPT4
- Automatically crops white-space to create smaller inputs
- Cleans up JSON string returned by the LLM and converts it to an JSON object
- Custom prompt support for capturing any data you need
- Supports several image formats as PNG, JPEG, JPG, GIF, and WebP
- Supports simple PDF files and complex multipage PDFs
Hazem Abbas
8- Safely send PDF documents to LLM
This open-source tool uses in-browser Tesseract OCR to extract and anonymize text from PDFs and images, removing PII before sharing with LLMs like ChatGPT.
It enhances OCR output for privacy-sensitive cases, making it suitable for secure use with health data and other critical documents.
9- AllCR App
The OCR App is a Streamlit-based tool that captures text from real-world objects, converting it into searchable JSON documents using OCR with GPT-4, AWS Bedrock, or Google Gemini.
Extracted data is stored in MongoDB Atlas, showcasing MongoDB's capabilities and LLM-agnostic integration. This demo highlights MongoDB’s versatility in managing OCR data across various LLMs.
Features
- Authentication: Secure access to the application using an API code.
- Image Capture: Capture images using your device's camera.
- OCR to JSON: Convert captured images to JSON format using OpenAI's GPT-4.
- MongoDB Integration: Store and retrieve the extracted information from MongoDB.
- Search and Display: Search and display stored documents along with their images.
- Chat with AI: Open the sidebar to chat with GPT on the context captured by the app.
10- LLaVAR: Enhanced Visual Instruction Tuning
LLaVAR is an open-source tool for performing visual question-answering tasks by combining language and vision AI models.
It processes visual data to provide accurate, context-based answers, enhancing applications that require insights from images or videos.
11- Swift OCR: LLM Powered Fast OCR ⚡
This open-source OCR API uses OpenAI's language models with parallel processing and batching to extract high-quality text from complex PDFs. It’s designed for efficient document digitization and data extraction, ideal for business applications.
Features
- Flexible Input Options: Accepts PDF files via direct upload or by specifying a URL.
- Advanced OCR Processing: Utilizes OpenAI's GPT-4 Turbo with Vision model for accurate text extraction.
- Performance Optimizations:
- Parallel PDF Conversion: Converts PDF pages to images concurrently using multiprocessing.
- Batch Processing: Processes multiple images in batches to maximize throughput.
- Retry Mechanism with Exponential Backoff: Ensures resilience against transient failures and API rate limits.
- Structured Output: Extracted text is formatted using Markdown for readability and consistency.
- Robust Error Handling: Comprehensive logging and exception handling for reliable operations.
- Scalable Architecture: Asynchronous processing enables handling multiple requests efficiently.
yigitkonur12- Nougat: Neural Optical Understanding for Academic Documents
Nougat is an open-source OCR tool by Facebook Research, designed for extracting text and data from scientific PDFs. It specializes in handling complex documents, including math equations, tables, and figures, making it highly useful for research papers and technical documents.
Nougat is trained to recognize scientific layouts and provides accurate, structured text output. It’s ideal for academics and researchers needing reliable text extraction from dense, technical PDFs.
13- Open Parse
Open-Parse is an open-source tool that extracts structured data from PDFs and documents, especially for unstructured formats. It is designed for parsing invoices, receipts, and other complex document layouts effectively.
Features
- PDF and Document Parsing: Extracts data from various document types.
- Structured Data Output: Converts unstructured text into structured data formats.
- Specialized for Invoices and Receipts: Tailored to handle complex layouts and formats.
- Open-Source: Freely available for customization and integration.
- Automated Data Extraction: Minimizes manual data entry and processing.
- Scalability: Suitable for large-scale document processing applications.
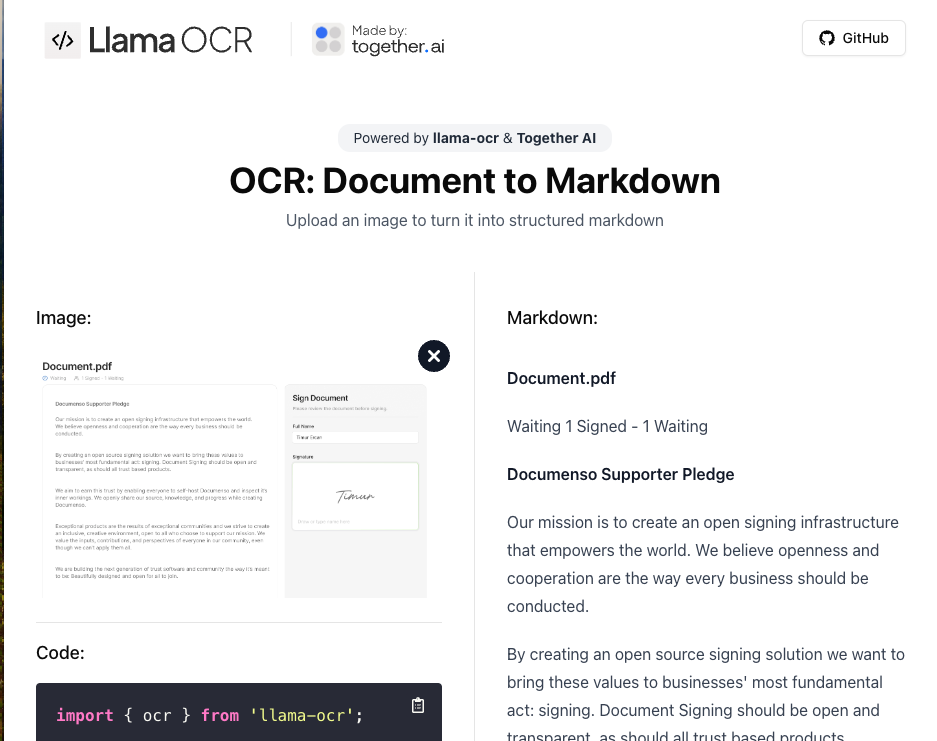
Filimoa14- LlamaOCR
Hazem Abbas