PyHealth: Open-source Deep Learning for Medical and Healthcare Apps

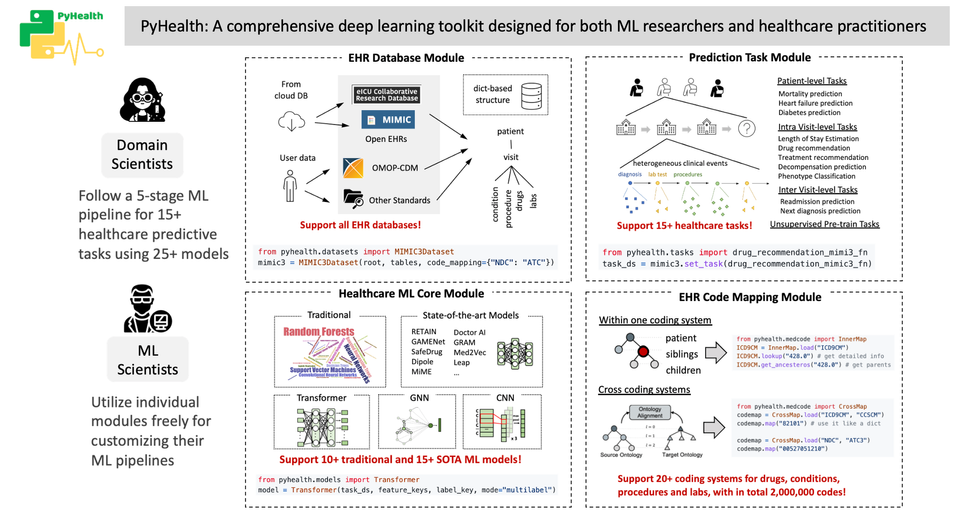
Table of Content
PyHealth is a comprehensive deep learning toolkit designed to support clinical predictive modeling. Tailored for both ML researchers and medical practitioners, it simplifies the development and deployment of healthcare AI applications. Our toolkit offers enhanced flexibility, customization options, and seamless integration, making it easier to implement advanced healthcare solutions.
 Hazem Abbas
Hazem Abbas
The project is developed by researchers from the University of Illinois Urbana-Champaign, PyHealth aims to simplify healthcare AI applications.
PyHealth is a completely open-source project available on GitHub, with 950 stars and 207 forks as of the last update. It's designed to make healthcare AI applications more accessible, flexible, and customizable for researchers and practitioners in the field.
Wide Range of AI Models:
PyHealth offers ready-to-use implementations of state-of-the-art ML models, including deep learning architectures. These models are tailored for healthcare applications like disease prediction, patient outcome prediction, and survival analysis.
Healthcare Data Specificity:
The project includes support for domain-specific data like EHRs, medical images, and wearable sensor data, making it a powerful tool for practitioners in healthcare settings.
Mohamed Youssef
Features
- Supports healthcare datasets (MIMIC-III, MIMIC-IV, eICU, OMOP-CDM)
- Offers ML models (CNN, LSTM, GRU, RETAIN, SafeDrug) for various healthcare tasks
- Five-stage customizable pipeline: datasets, tasks, models, trainer, metrics
- Medical code mapping and tokenization for data processing
- User-friendly APIs for handling complex healthcare ML tasks
- Wide range of healthcare-specific models and interpretability tools
- Supports EHR, medical images, and wearable sensor data
- Open-source with extensive documentation and community support
- Preprocessing pipelines and cross-domain applicability
- Dozens of tutorials and developer-friendly docs.
Benefits and Use-cases
- EHR data handling: Built-in support for processing longitudinal EHR data, including temporal relationships in medical records.
- Disease Prediction Models: Various machine learning models are available to predict diseases based on healthcare data.
- Survival Analysis: Models for estimating patient survival times and outcomes.
- Wearable and Sensor Data Support: It includes tools for processing data from wearable devices, a critical component of modern healthcare data collection.
- Preprocessing Pipelines: PyHealth automates many of the data preprocessing steps (like normalization, data imputation) required for machine learning models.
- Cross-domain Applicability: While tailored for healthcare, PyHealth can also be extended to other domains where time-series or sensor data are involved.
- Model Interpretation: PyHealth includes tools to interpret model outputs, essential in healthcare for explaining decisions to medical professionals.
How does it work?
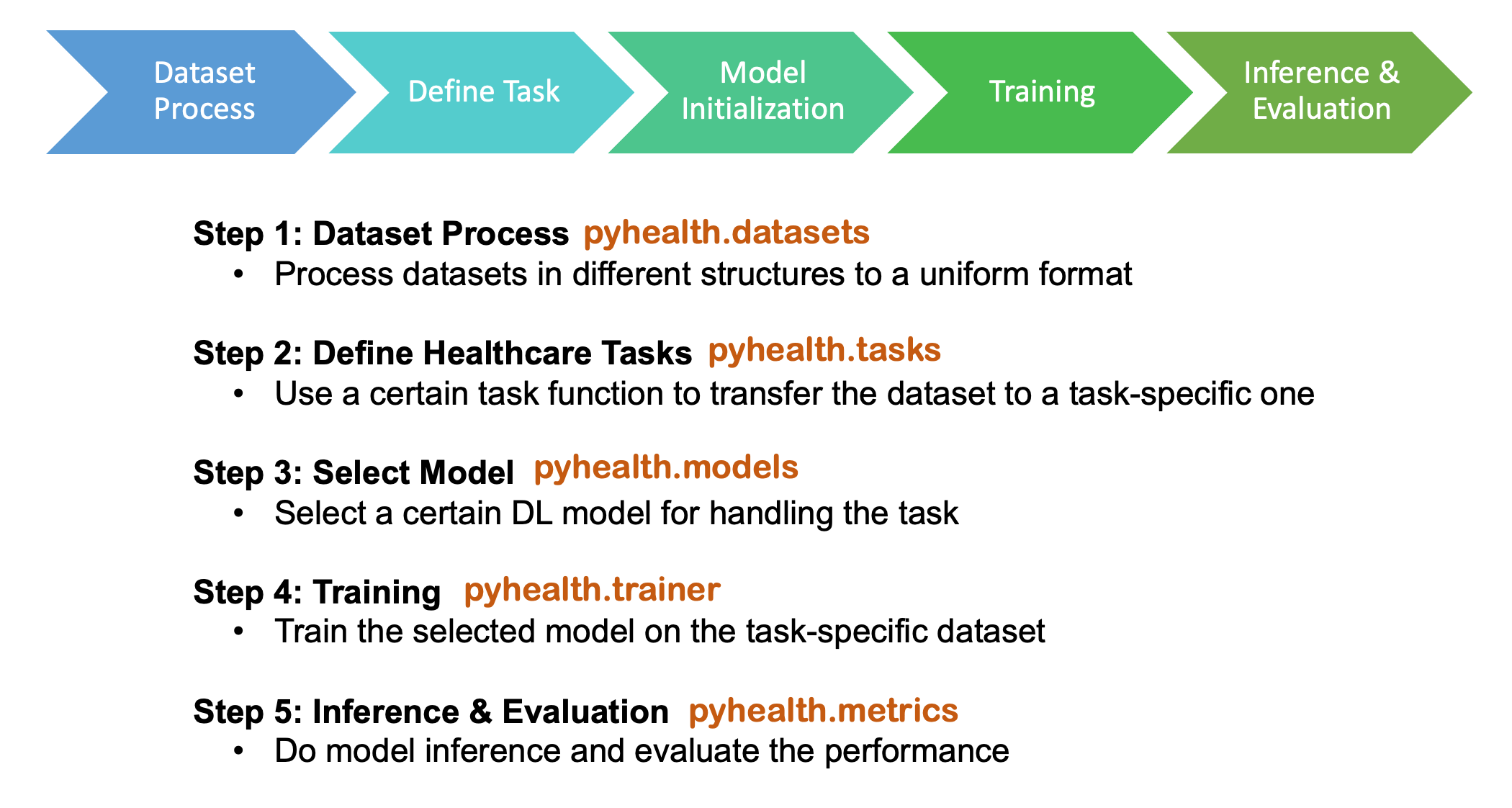
PyHealth works by providing a set of pre-built components for healthcare-related machine learning tasks, simplifying the workflow from data preprocessing to model development and evaluation. Here's a step-by-step explanation of how the package works:
1. Data Handling:
- Electronic Health Records (EHR): PyHealth supports longitudinal EHR data, which consists of patient medical records collected over time. It handles the structured and unstructured nature of healthcare data, such as diagnoses, medication, and lab results.
- Wearable & Sensor Data: It supports time-series data from wearables, enabling machine learning models for healthcare monitoring applications.
- Data Loaders: PyHealth comes with data loaders designed specifically for medical datasets, transforming raw data into suitable input formats for machine learning models.
2. Data Preprocessing:
- Normalization & Data Imputation: Missing data is a common issue in healthcare, and PyHealth provides built-in methods for imputing missing values (e.g., through interpolation or statistical methods).
- Temporal Data Handling: PyHealth handles temporal dependencies in medical data, which is crucial when analyzing patient health trajectories over time.
- Feature Extraction: Key features, like patient vitals, lab results, or sensor readings, are extracted and engineered in a way that ML models can easily consume.
3. Model Selection & Building:
- PyHealth offers various pre-built machine learning and deep learning models designed for healthcare use cases. These include models for:
- Disease Prediction: Predicting the onset of diseases based on historical health records.
- Survival Analysis: Estimating the time until an event (e.g., death, hospital readmission).
- Patient Outcome Prediction: Predicting patient outcomes, such as recovery or complications, based on previous data.
- Some of the models available include RNNs, LSTMs, and transformer-based models, which are ideal for time-series and sequential data.
4. Model Training & Evaluation:
- Training Pipelines: PyHealth automates the process of training machine learning models, allowing for rapid iteration and prototyping. Users can define their own loss functions, optimizers, and hyperparameters.
- Evaluation Metrics: The library provides built-in evaluation metrics that are critical in healthcare, such as ROC-AUC, precision-recall, survival analysis metrics (e.g., concordance index), and calibration curves for model interpretability.
- Cross-validation: PyHealth supports cross-validation to evaluate model robustness and prevent overfitting.
5. Model Interpretation:
- In healthcare, model transparency is crucial, so PyHealth provides mechanisms to interpret model outputs. It can generate attention maps and highlight features that are important in decision-making.
- This step ensures that healthcare professionals can understand why a model is making certain predictions, enhancing trust and reliability.
6. Customization:
- PyHealth's modular structure allows users to customize almost every part of the machine learning pipeline. Developers can plug in their own data loaders, models, or even evaluation metrics, making the package adaptable to various healthcare problems.
Example Workflow:
Here’s a simple workflow for using PyHealth:
Evaluate Model: Evaluate the model on test data using appropriate metrics.
from pyhealth.evaluation import evaluate_model
evaluation_metrics = evaluate_model(model, test_data)
Train Model: Train the model with the dataset.
from pyhealth.training import train_model
model = train_model(model, processed_data)
Select Model: Choose a pre-built model (e.g., for disease prediction).
from pyhealth.models import LSTM
model = LSTM(input_size, hidden_size, output_size)
Preprocess Data: Use the preprocessing utilities to handle missing values, normalize data, and extract features.
from pyhealth.preprocessing import preprocess_ehr
processed_data = preprocess_ehr(dataset)
Load Data: Load EHR or sensor data using PyHealth’s data loader.
from pyhealth.datasets import load_ehr_data
dataset = load_ehr_data(data_path)
In summary, PyHealth simplifies the entire machine learning pipeline, from loading and preprocessing healthcare data to training, evaluating, and interpreting models, while offering flexibility for customization.
License
PyHealth is released as an open-source project under the MIT License.
Resources & Downloads
 sunlabuiuc
sunlabuiuc