Swiple: Open-source Automated Data Monitoring
The data quality automation plugin for data teams. Experience data quality observability in your ELT/ETL pipeline that would usually take a year to build, in just a few hours.

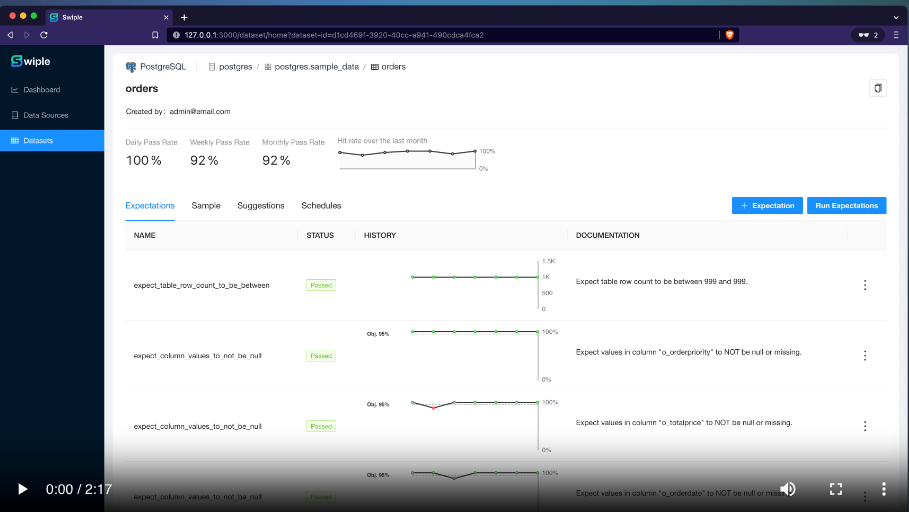
Swiple is an automated data monitoring platform that provides a comprehensive solution for analytics and data engineering teams to seamlessly monitor and manage the quality of their data. The platform offers a range of features that are designed to ensure that data quality is maintained at all times, thus allowing teams to focus on other critical tasks. One of the key features that sets Swiple apart from other data monitoring platforms is its ability to provide real-time alerts in case of any data inconsistencies or anomalies.
This ensures that teams can quickly identify and address any issues, reducing the risk of data errors and improving overall data quality. Additionally, Swiple offers a user-friendly interface that allows teams to easily manage and monitor data across multiple sources, providing a centralized view of data quality across the organization.
With Swiple, teams can streamline their data monitoring processes, reduce manual effort, and ultimately improve the accuracy and reliability of their data.
Features
- Easy setup
- Zero config
- Measure the data quality of a SQL query, table, or view.
- Generate data expectations using Automated Data Profiling.
- Schedule validations to run on any recurrence interval.
- Automated Data Docs
- Add Objectives / SLA's for your data.
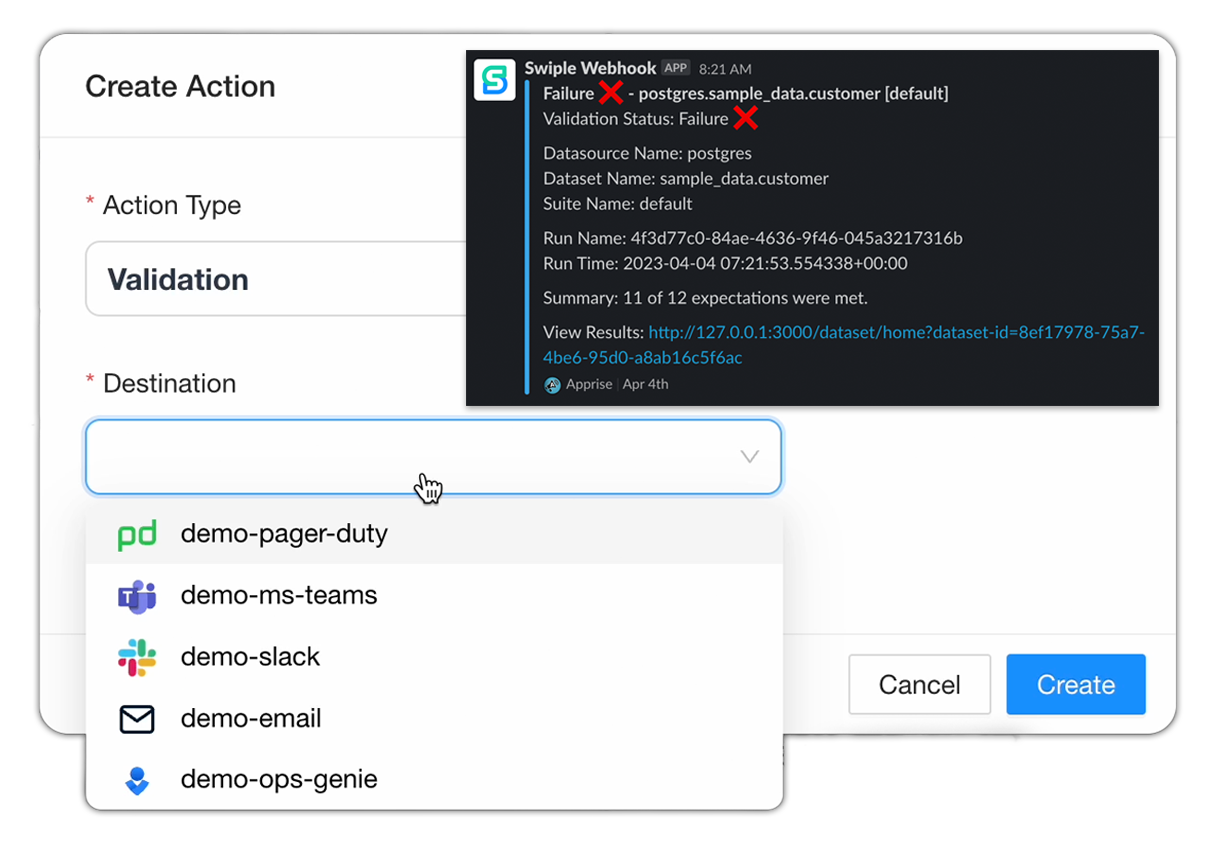
- Get notified when the quality of your data changes.
- Notifications using Slack, Email, Microsoft Teams, OpsGenie, and PagerDuty
With Swiple, analytics and data engineering teams can resolve data quality issues before they impact mission-critical resources. The platform offers automated data analysis and profiling, scheduling and alerting to ensure data quality is maintained.
Supported Databases
- MySQL
- MariaDB
- PostgreSQL
- Redshift
- BigQuery
- Snowflake
- Trino
- Athena
Platforms
- Windows
- Linux
- macOS
License
- Copyright 2022 Swiple, Ltd.
- The Source code in this Swiple repo is covered by the Elastic License 2.0.
Resources
 Swiple
Swiple