TiefVision Is a Deep-Learning Image Search Engine

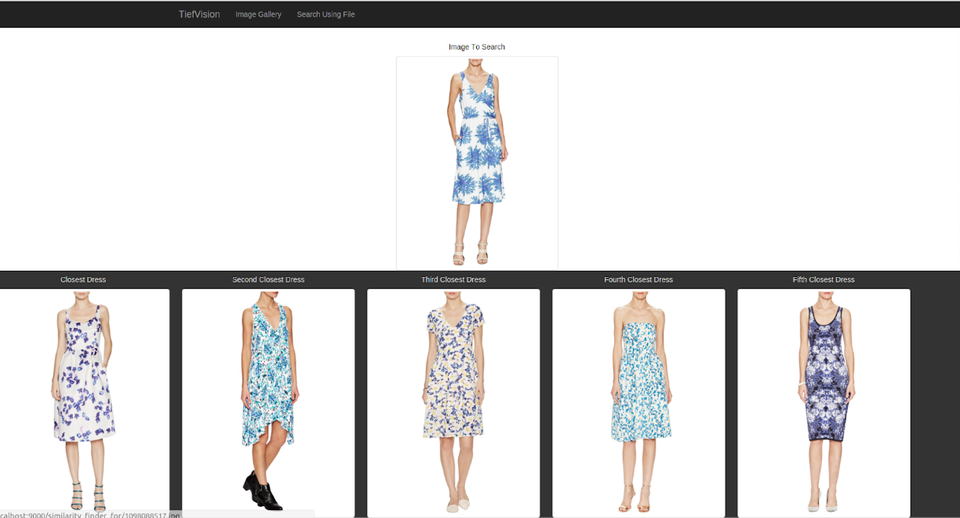
Table of Content
TiefVision is an end-to-end deep learning image-similarity search engine.
TiefVision is an integrated end-to-end image-based search engine based on deep learning. It covers image classification, image location (OverFeat) and image similarity (Deep Ranking).
TiefVision is implemented in Torch and Play Framework (Scala version). It currently only supports Linux with CUDA-enabled GPU.
The project is divided into two module groups: Deep Learning Modules and Tooling Modules.
Deep Learning Modules
The deep learning modules included in TiefVision are the following:
1- Transfer Learning
TiefVision transfers a simplified (without grouping) AlexNet network that is used for encoding purposes. The steps involved in the transfer learning phase are the following:
- It splits an already trained AlexNet neural network without grouping into two neural networks:
- The lower convolutional part that acts as an encoder of high-level features (“image encoder")
- The upper/top fully connected part that is discarded as it’s meant to classify images for other purposes (ImageNet classification).
- It reduces the last max pooling step size from the encoder neural network (lower-part) to increase the spatial accuracy.
2- Image Classification
The image classification module performs the following steps:
- It encodes all the crops from the target image (e.g. dresses) and its background using the encoder neural network:
- Target Image Crops: crops of the images in such a way at least 50% of the crop is inside the target image bounding box. For a dataset of dresses, at least 50% of the crop contains a dress (it can include up to 50% of the background).
- Background Image Crops: crops of the images in such a way at least 50% of the crop contains the target image background. For the example of dresses, at least 50% of the crop contains background.
- It trains a fully connected neural network to classify the target image crops (e.g. dresses) and its background crops (e.g. photo studio background).
3- Image Location (based on OverFeat)
The image location module perform the following steps:
- It encodes the Target Image Crop's dataset together with its normalized bounding box delta (distance between the bounding box upper-left point and the bounding box coordinates).
- It trains four fully connected neural networks to predict the two relative bounding box points:
- Two neural networks for the two dimensions of the upper-left point.
- Two neural networks for the two dimensions of the lower-right point.
- It extracts the bounding box filtering out background crops using the image classification neural network and averaging the bounding boxes using the bounding box neural network.
4- Image Similarity (based on Deep Ranking)
The similarity is based on the distance between two image encodings. TiefVision trains a neural network to map encoded images into a space in which the dot product acts as a similarity distance between images. As the encodings are normalized, the dot product computes the cosine of the angle between the encodings.
Given the following triplets of images:
- H: a reference image
- H+: an image similar to the reference image (H).
- H-: another image that is similar to H but not as similar as H+.
It trains a neural network to make H+ closer to H than H- using the Hinge loss: l(H, H+, H-) = max(0, margin + D(H, H+) - D(H, H-)) where D is the dot product of the two images mapped into the neural network’s output space: D(H1, H2) = NN(H1) · NN(H2)
Tooling Modules
TiefVision includes a set of web tools to ease the generation of datasets and thus increase productivity.
The current tools are the following:
- Visual Bounding Box Database Editor
- Visual Similarity Database Editor
- Web File-based Image Search
- Image Gallery Browser (search upon click)
- Automated Train and Test dataset generation for:
- Image (crop) classification
- Bounding box regression
- Image Similarity (Deep Ranking)
License and Copyright
Copyright (C) 2016 Pau Carré Cardona - All Rights Reserved You may use, distribute and modify this code under the terms of the Apache License v2.