Vocode - Build Voice-enabled AI Apps with this Amazing Open-source Python Framework

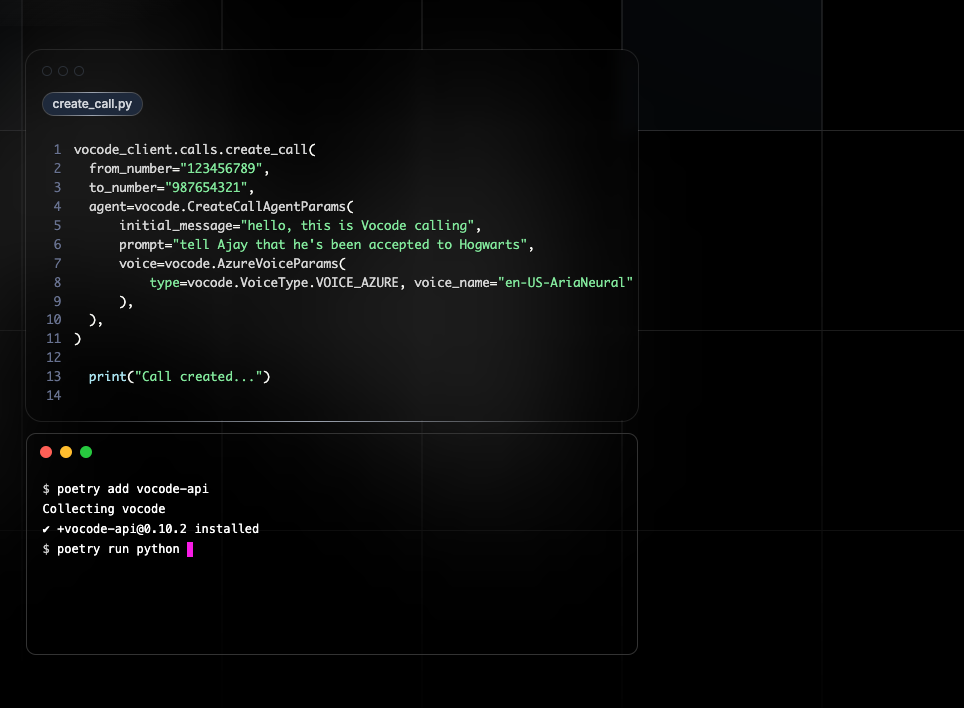
Table of Content
Vocode is an open-source library that simplifies building voice-enabled applications powered by large language models (LLMs). It allows developers to create real-time, voice-based conversations with LLMs and deploy them to phone calls, Zoom meetings, and beyond.
With Vocode, you can build interactive apps like personal assistants or voice-controlled games such as chess.
It provides easy-to-use integrations and abstractions, streamlining the development of voice-enabled apps, making LLM interactions more accessible through voice interfaces.
Features
- 🗣 Real-time Conversations: Initiate voice-based conversations directly with your system audio using LLMs.
- ➡️ 📞 Phone Number Setup: Set up phone numbers that interact with LLM-based agents for automated responses.
- 📞 ➡️ Outbound Phone Calls: Send calls from your managed phone numbers powered by LLM-based agents.
- 🧑💻 Zoom Call Integration: Dial into Zoom meetings with voice-enabled LLMs.
- 🤖 Langchain Agent Integration: Make outbound calls to real phone numbers using LLMs via Langchain agents.
- Ultra-Realistic Voices: Choose from a wide selection of highly realistic voices to enhance customer experiences.
- Multilingual Capability: Configure bots to communicate in multiple languages, offering native language support for your customers.
- Custom Language Models: Utilize your own language models to create bots with personalized, context-specific communication.
- External Action Integration: Automate tasks such as scheduling, payments, and more by integrating with external systems.
- Phone Menu Navigation: Bots can navigate phone menus to reach the appropriate department or individual.
- Hold Waiting: Bots can wait on hold for you and transfer the call once a human agent is available.
- Knowledge Base Connection: Enhance bots with knowledge from your own resources to improve their responses and intelligence.
- Analytics and Monitoring: Track bot performance and customer interactions for valuable insights.
- Available 24/7: Bots are always active, scaling up or down as needed, eliminating the need for hiring, training, or managing human agents.
Out-of-the-box Integrations
- Transcription Services:
- AssemblyAI
- Deepgram
- Gladia
- Google Cloud
- Microsoft Azure
- RevAI
- Whisper
- Whisper.cpp
- LLMs:
- OpenAI
- Anthropic
- Synthesis Services:
- Rime.ai
- Microsoft Azure
- Google Cloud
- Play.ht
- Eleven Labs
- Cartesia
- Coqui (OSS)
- gTTS
- StreamElements
- Bark
- AWS Polly
Install
pip install vocodeUsage
import asyncio
import signal
from pydantic_settings import BaseSettings, SettingsConfigDict
from vocode.helpers import create_streaming_microphone_input_and_speaker_output
from vocode.logging import configure_pretty_logging
from vocode.streaming.agent.chat_gpt_agent import ChatGPTAgent
from vocode.streaming.models.agent import ChatGPTAgentConfig
from vocode.streaming.models.message import BaseMessage
from vocode.streaming.models.synthesizer import AzureSynthesizerConfig
from vocode.streaming.models.transcriber import (
DeepgramTranscriberConfig,
PunctuationEndpointingConfig,
)
from vocode.streaming.streaming_conversation import StreamingConversation
from vocode.streaming.synthesizer.azure_synthesizer import AzureSynthesizer
from vocode.streaming.transcriber.deepgram_transcriber import DeepgramTranscriber
configure_pretty_logging()
class Settings(BaseSettings):
"""
Settings for the streaming conversation quickstart.
These parameters can be configured with environment variables.
"""
openai_api_key: str = "ENTER_YOUR_OPENAI_API_KEY_HERE"
azure_speech_key: str = "ENTER_YOUR_AZURE_KEY_HERE"
deepgram_api_key: str = "ENTER_YOUR_DEEPGRAM_API_KEY_HERE"
azure_speech_region: str = "eastus"
# This means a .env file can be used to overload these settings
# ex: "OPENAI_API_KEY=my_key" will set openai_api_key over the default above
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
extra="ignore",
)
settings = Settings()
async def main():
(
microphone_input,
speaker_output,
) = create_streaming_microphone_input_and_speaker_output(
use_default_devices=False,
)
conversation = StreamingConversation(
output_device=speaker_output,
transcriber=DeepgramTranscriber(
DeepgramTranscriberConfig.from_input_device(
microphone_input,
endpointing_config=PunctuationEndpointingConfig(),
api_key=settings.deepgram_api_key,
),
),
agent=ChatGPTAgent(
ChatGPTAgentConfig(
openai_api_key=settings.openai_api_key,
initial_message=BaseMessage(text="What up"),
prompt_preamble="""The AI is having a pleasant conversation about life""",
)
),
synthesizer=AzureSynthesizer(
AzureSynthesizerConfig.from_output_device(speaker_output),
azure_speech_key=settings.azure_speech_key,
azure_speech_region=settings.azure_speech_region,
),
)
await conversation.start()
print("Conversation started, press Ctrl+C to end")
signal.signal(signal.SIGINT, lambda _0, _1: asyncio.create_task(conversation.terminate()))
while conversation.is_active():
chunk = await microphone_input.get_audio()
conversation.receive_audio(chunk)
if __name__ == "__main__":
asyncio.run(main())License
MIT License
Resources & Downloads
GitHub - vocodedev/vocode-core: 🤖 Build voice-based LLM agents. Modular + open source.
🤖 Build voice-based LLM agents. Modular + open source. - vocodedev/vocode-core
 vocodedev
vocodedevVocode - Open source voice AI agents