WEKA: Open source Machine Learning Tools for Developers

WEKA (Waikato Environment for Knowledge Analysis) is a collection of machine learning algorithms for data mining tasks. It contains tools for data preparation, classification, regression, clustering, association rules mining, and visualization. It also supports Deep Learning.
It is written in Java and developed at the University of Waikato, New Zealand. Weka is open source software released under the GNU General Public License.
Weka provides access to SQL databases using Java Database Connectivity (JDBC) and allows using the response for an SQL query as the source of data. This tool doesn’t support processing of related charts; however, there are many tools allowing combining separate charts into a single chart, which can be loaded right into Weka.
There are two versions of Weka: Weka 3.8 is the latest stable version and Weka 3.9 is the development version. For the bleeding edge, it is also possible to download nightly snapshots. Stable versions receive only bug fixes, while the development version receives new features.
Weka 3.8 and 3.9 feature a package management system that makes it easy for the Weka community to add new functionalities to Weka.
User Interfaces:
It has 5 user interfaces:
1- Simple CLI:
Provides full access to all Weka classes, i.e., classifiers, filters, clusterers, etc., but without the hassle of the CLASSPATH. It offers a simple Weka shell with separated commandline and output.
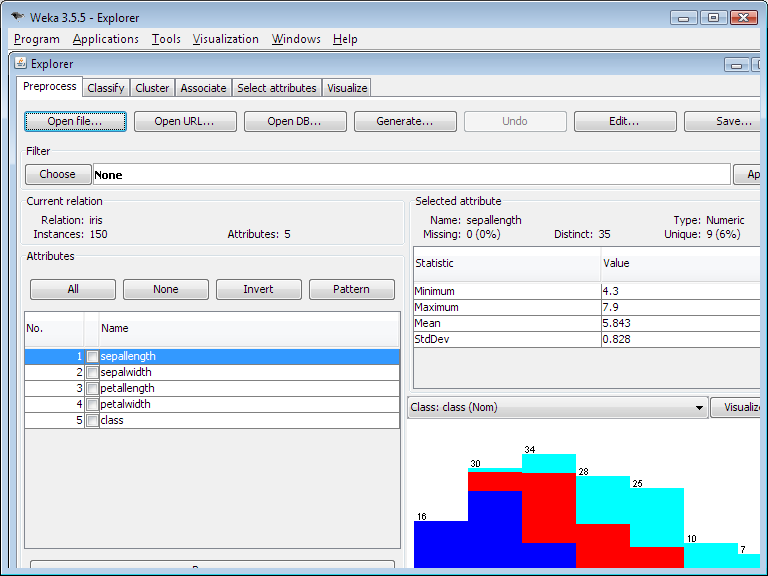
2- Explorer:
An environment for exploring data with WEKA. It has different tabs:
- Preprocess: which enables you to choose and modify the data being acted on.
- Classify: to train and test learning schemes that classify or perform regression.
- Cluster: to learn clusters for the data.
- Associate: to learn association rules for the data.
- Select attributes: to select the most relevant attributes in the data.
- Visualize: which enables you to view an interactive 2D plot of the data.
3- Experimenter:
An environment that enables the user to create, run, modify, and analyse experiments in a more convenient manner than is possible when processing the schemes individually
4- KnowledgeFlow:
Supports essentially the same functions as the Explorer but with a drag-and-drop interface. The KnowledgeFlow can handle data either incrementally or in batches (the Explorer handles batch data only).
5- Workbench:
A new user interface which is available from Weka 3.8.0. The Workbench provides an all-in-one application that subsumes all the major WEKA GUIs described above.
Highlights:
- Cross-Platform support (Windows, Mac OS X and Linux).
- Free open source.
- Ease of use (includes a GUI).
- A comprehensive collection of data preprocessing and modelling techniques.
- Supports Deep Learning.
Packages:
Weka has a large number of regression and classification tools. Some examples are:
- BayesianLogisticRegression: Implements Bayesian Logistic Regression for both Gaussian and Laplace Priors.
- BayesNet: Bayes Network learning using various search algorithms and quality measures.
- GaussianProcesses: Implements Gaussian Processes for regression without hyperparameter-tuning.
- LinearRegression: Class for using linear regression for prediction.
- MultilayerPerceptron: A Classifier that uses backpropagation to classify instances.
- NonNegativeLogisticRegression: Class for learning a logistic regression model that has non-negative coefficients.
- PaceRegression: Class for building pace regression linear models and using them for prediction.
- SMO: Implements John Platt's sequential minimal optimization algorithm for training a support vector classifier.
- ADTree: Class for generating an alternating decision tree.
- BFTree: Class for building a best-first decision tree classifier.
- HoeffdingTree: A Hoeffding tree (VFDT) is an incremental, anytime decision tree induction algorithm that is capable of learning from massive data streams, assuming that the distribution generating examples does not change over time.
- M5P: M5Base. Implements base routines for generating M5 Model trees and rules.
- RandomForest: Class for constructing a forest of random trees.
- RandomTree: Class for constructing a tree that considers K randomly chosen attributes at each node. Performs no pruning.
- SimpleCart: Class implementing minimal cost-complexity pruning.
- IBk: K-nearest neighbours classifier. Can select appropriate value of K based on cross-validation. Can also do distance weighting.
- IB1: Nearest-neighbour classifier.
- LBR: Lazy Bayesian Rules Classifier.
- DecisionTable: Class for building and using a simple decision table majority classifier.
- M5Rules: Generates a decision list for regression problems using separate-and-conquer. In each iteration it builds a model tree using M5 and makes the "best" leaf into a rule.
- ZeroR: Class for building and using a 0-R classifier. Predicts the mean (for a numeric class) or the mode (for a nominal class).
- ClassificationViaRegression: Class for doing classification using regression methods.
- Stacking: Combines several classifiers using the stacking method. Can do classification or regression.
- DataNearBalancedND: A meta classifier for handling multi-class datasets with 2-class classifiers by building a random data-balanced tree structure.
- MDD: Modified Diverse Density algorithm, with collective assumption.
- MINND: Multiple-Instance Nearest Neighbour with Distribution learner.
License:
GNU General Public License.
References:
Conclusion:
WEKA is a good choice for first time introduction to machine learning even for non-programmers due to the simplicity of the GUI interface.



