15 Open-source Text To Speech TTS Apps and Libraries


Table of Content
What is Text-to-Speech?
Text-to-speech or speech synthesis is an artificially generated human-sounding speech from text that recognize words and formulate human speech.
The first Text-To-Speech system was introduced to the world in 1968 by Noriko Umeda et al, at the Electrotechnical Laboratory in Japan.
In 1961, physicist John Larry Kelly, Jr and his colleague Louis Gerstman used an IBM 704 computer to synthesize speech, an event among the most prominent in the history of Bell Labs.
 Hamza Mousa
Hamza Mousa
The benefits of TTS?
The primary advantageous of this technology are people with visual and reading impairments, as they were its first users.
Nowdays, many YouTube channels use this technology in order to minimize their edit and increase their production.
In many modern operating system, Text-to-speech is a built-in accessibility feature to assist people who cannot read on-screen text easily.
About this list
In this article we offer you our collection of free, open-source Text-To-Speech (TTS) and speech synthesis apps. You can also find a new updated list for more open-source web-based TTS apps and services.
1- MARY TTS
MARY TTS is an open-source, multilingual text-to-speech synthesis system written in pure java. It is available for Windows, Linux, and macOS.
MARY TTS is released under the LGPL-3.0 License.
 marytts
marytts2- Kaldi
Kaldi is a toolkit for speech recognition written in C++ and licensed under the Apache License v2.0.The source code is available at GitHub.
Kaldi can run on Windows, Linux, and macOS. It also can run on Android, PowerPC, and with Web Assembly.

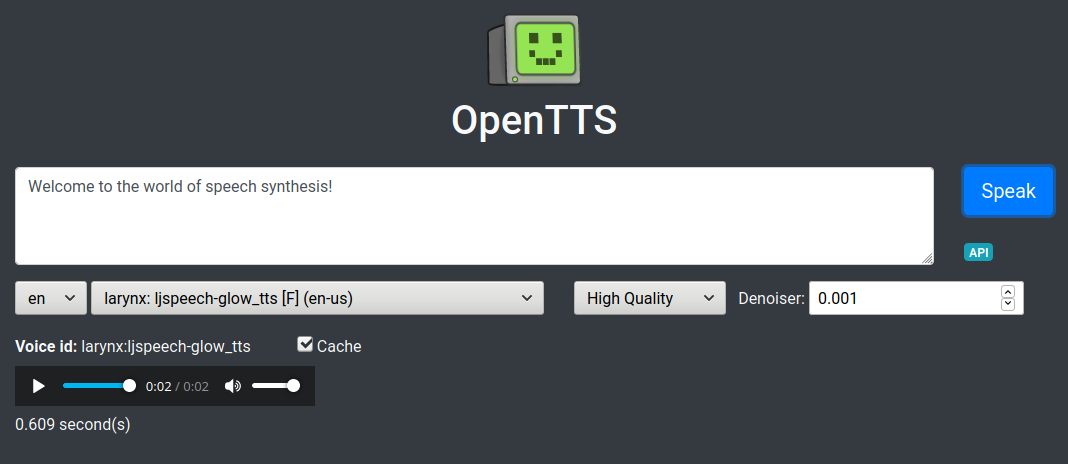
3- OpenTTS
OpenTTS is a free, open-source Open Text to Speech Server written in Python. It is released under the MIT License. It supports several languages, and comes with an easy-to-use interface. Furthermore, it comes with numerous alternatives libraries.
Supported languages: English (27), German (7), French (3), Spanish (2), Dutch (4), Russian (3), Swedish (1), Italian (2), Swahili (1), Finnish, Korean, Japanese, Chinese, Swedish, and more.
synesthesiam4- eSpeak
eSpeak is a compact open source software speech synthesizer for English and other languages, for Linux and Windows. It supports several languages, and comes with dozens of useful features, which makes it the ideal choice for many users.
Supported languages
Afrikaans, Albanian, Aragonese, Armenian, Bulgarian, Cantonese, Catalan, Croatian, Czech, Danish, Dutch, English, Esperanto, Estonian, Farsi, Finnish, French, Georgian, German, Greek, Hindi, Hungarian, Icelandic, Indonesian, Irish, Italian, Kannada, Kurdish, Latvian, Lithuanian, Lojban, Macedonian, Malaysian, Malayalam, Mandarin, Nepalese, Norwegian, Polish, Portuguese, Punjabi, Romanian, Russian, Serbian, Slovak, Spanish, Swahili, Swedish, Tamil, Turkish, Vietnamese, Welsh.
5- Text To Speech Converter
This open-source project allows you to convert any text into speech easily by copying and paste the text into its simple interface. It is written in C# programming languages and runs on Windows for now.
avi-jkiapt6- ONLINE TTS
ONLINE TTS is a simple HTML/ JavaScript project that turns your English text into a formidable speech.
ONLINE TTS features simple shortcuts, and a clean user-interface.
therealvasanth7- Flite
Flite is a small, fast run-time synthesis library suitable for embedded systems and servers. The core Flite library was developed by Alan W Black [email protected] (mostly in his so-called spare time) while employed in the Language Technologies Institute at Carnegie Mellon University.
Flite supports Windows, Linux, macOS, Android, FreeBSD, and several other systems.

8- Julius
Julius is an open-source large vocabulary continuous speech recognition engine.
It is a high-performance, small-footprint large vocabulary continuous speech recognition (LVCSR) decoder software for speech-related researchers and developers. Based on word N-gram and context-dependent HMM.
Hamza Mousa
9- Athena
Athena is an open-source implementation of sequence-to-sequence based speech processing engine
Athena features
Hybrid Attention/CTC based end-to-end ASR
- Speech-Transformer
- Unsupervised pre-training
- Multi-GPU training on one machine or across multiple machines with Horovod
- End-to-end Tacotron2 based TTS with support for multi-speaker and GST
- Transformer based TTS and FastSpeech
- WFST creation and WFST-based decoding
- Deployment with Tensorflow C++
athena-team10- ESPnet: end-to-end speech processing toolkit
ESPnet is an end-to-end speech processing toolkit, mainly focuses on end-to-end speech recognition and end-to-end text-to-speech.
It is a developer-friendly application that can integrated into web projects. Developers also can install it using Docker.
11- Voice Builder
Voice Builder is an open source text-to-speech (TTS) voice building tool that focuses on simplicity, flexibility, and collaboration. Our tool allows anyone with basic computer skills to run voice training experiments and listen to the resulting synthesized voice.
The Voice Builder project is written using JavaScript and released under the Apache-2.0 License.
google12- Coqui TTS
Coqui TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality.
coqui-ai13- Mozilla TTS
Mozilla TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality.
mozilla14- Mycoft Mimic
Mycroft is an open-source voice assistant system. Mimic is the built-in TTS library created by Mycroft team.
15- Free TTS
Hamza Mousa
If you know any other open-source TTS application, toolkit, or library that we didn't mention here, let us know.
Hamza Mousa Ayesha Khizer
Ayesha Khizer Hamza Mousa
Hamza Mousa