19 Open-source Free Website Copier and Website Cloner Apps for Offline Browsing


Website Copier and Website Cloner apps are tools designed to download websites and their content for offline browsing purposes. They allow users to create local copies of websites, including HTML, CSS, JavaScript, images, and other files, so that they can be accessed without an internet connection.
Why you may need a site copier?
These apps are useful for various use-cases, including education, productivity, web archiving, and more.
Use-Cases:
- Offline Browsing: Website Copier and Website Cloner apps enable users to browse websites offline, without relying on an internet connection. This is particularly beneficial in situations where internet access is limited or unreliable.
- Web Archiving: These apps are commonly used for web archiving purposes, allowing users to create preserved copies of websites for historical or research purposes. Web archivists can use these tools to capture and store web content that may change or disappear over time.
- Education and Research: Website Copier and Website Cloner apps can be valuable for students, researchers, and educators who need to access online resources offline. By downloading websites, they can have uninterrupted access to relevant information, articles, papers, and other educational materials.
- Productivity: These apps can enhance productivity by enabling users to access websites and their content offline. This can be beneficial for professionals who frequently reference online documentation, tutorials, or other resources while working.
Audience
The audience for Website Copier and Website Cloner apps is diverse and can include:
- Students and researchers who require offline access to web resources for academic purposes.
- Web archivists who aim to preserve websites for future reference or historical documentation, they often use tools as ArchiveBox.
- Professionals in various fields who rely on web content for their work and need offline access.
- Individuals with limited internet connectivity, such as those in remote areas or during travel.
- Anyone who wants to create a personal offline archive of their favorite websites or online content.
Overall, Website Copier and Website Cloner apps provide a convenient solution for downloading websites and accessing their content offline, catering to the needs of different users in education, productivity, web archiving, and more.
In this list, we offer you the best open-source web copier apps that you can download and use completely for free. Please note that they vary in features, and some may require skilled users to install and run.
1- HTTrack
HTTrack is a free and open-source website copying utility that allows you to download a website from the Internet to a local directory.
It creates a replica of the website's directory structure and saves it on your computer, allowing you to browse the website offline. This can be useful for tasks such as offline browsing, website archiving, or creating backups of websites.
 Hmza
Hmza
2- Getleft
Getleft is a free and open-source website download tool similar to HTTrack. It allows you to download complete websites or parts of websites to your local computer, enabling offline browsing and archiving.
Getleft is available for multiple platforms and provides features such as resuming interrupted downloads and filtering files based on size or type.
Hazem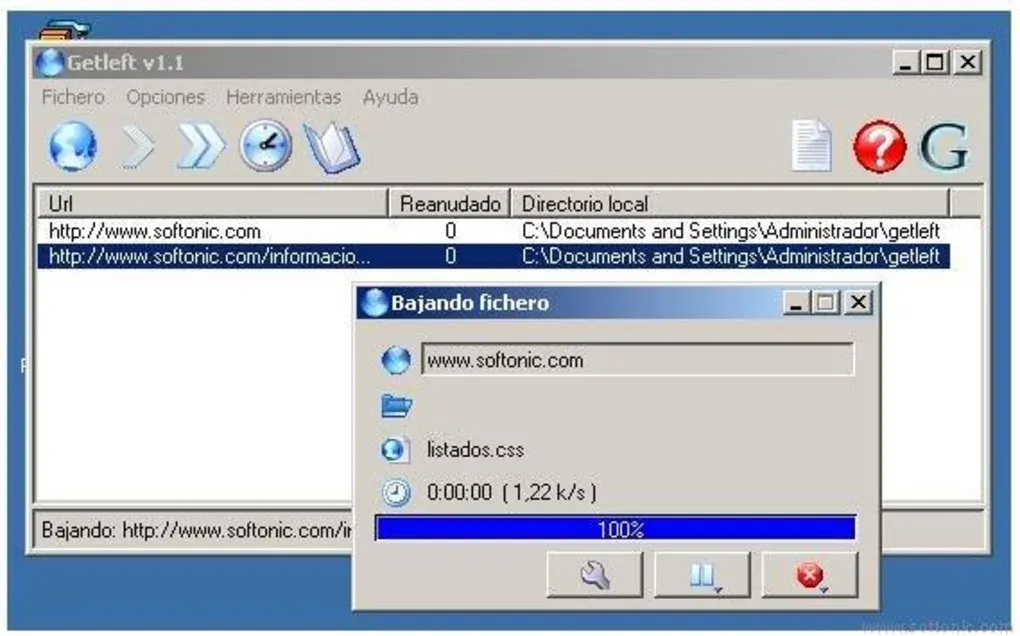

3- GoClone
GoClone is an open-source command-line tool written in Go Language that allows you to clone websites. It provides similar functionality to HTTrack and Getleft, allowing you to download websites or specific parts of websites for offline browsing or archiving purposes.
GoClone offers features such as recursive downloading, filtering options, and customizable configuration settings.
Hazem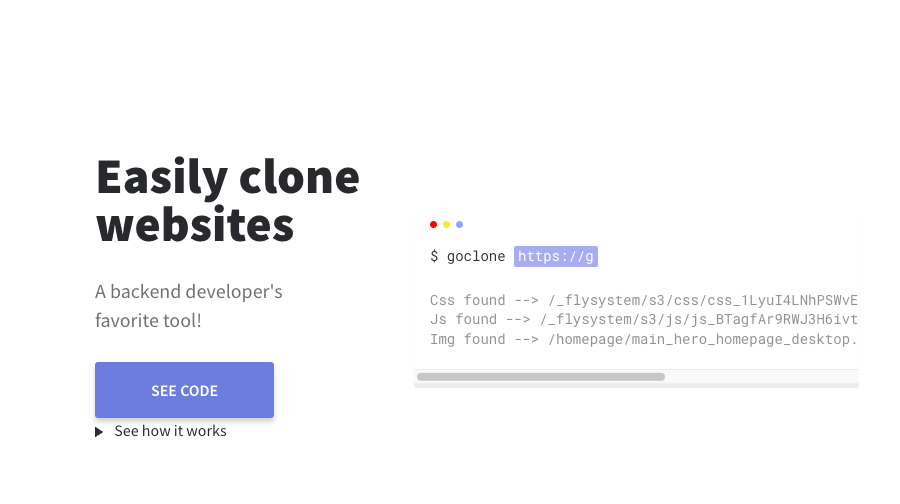
 imthaghost
imthaghost4- HTTraQt
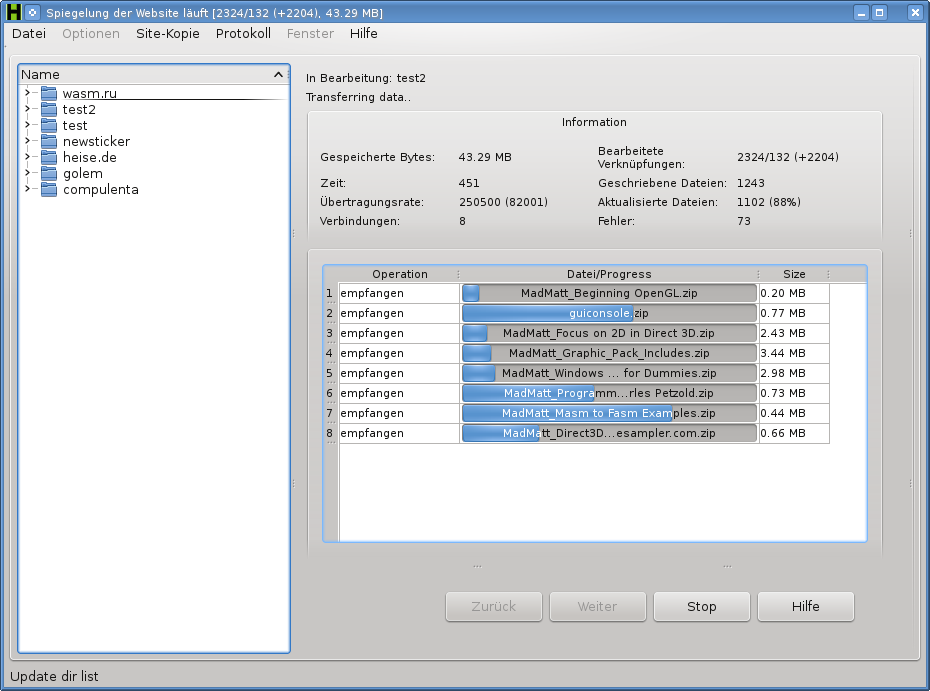
HTTraQt is a software clone of WinHTTrack that allows for downloading internet sites and their content. It offers features such as easy language switching, adding language files without changing the program code, selecting browsers and user agents, and extended file extension selection.
It was developed for Linux/ Unix/BSD but can be modified for Windows and Mac OSX. The software has a multilingual user interface and is compatible with Qt4 and Qt5.
The app is released under the GNU General Public License version 3.0 (GPLv3).
5- Website Scraper
The open-source website-scraper allows users to download a website to a local directory, including all CSS, images, and JS files. However, it does not execute JS, so dynamic websites may not be saved correctly.
For downloading dynamic websites, consider using website-scraper-puppeteer.
website-scraper6- Web Book Downloader
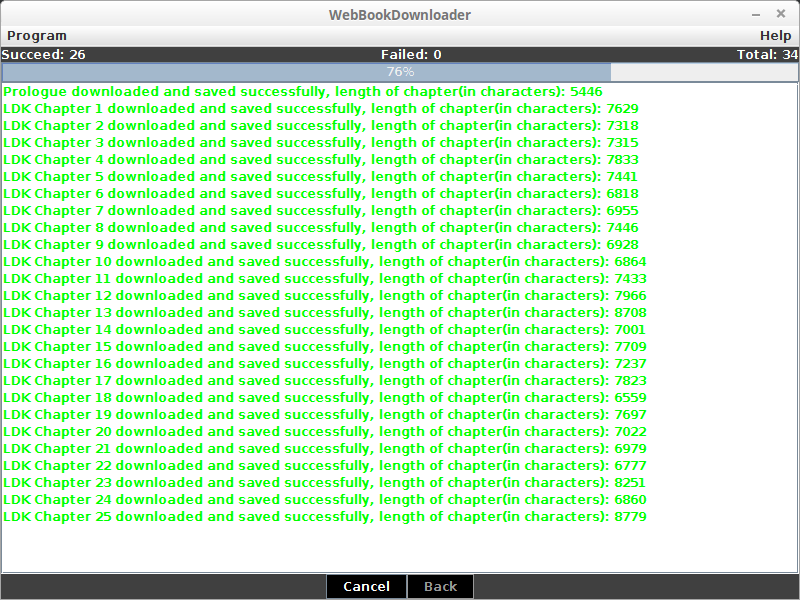
The Web Book Downloader application allows users to download chapters from a website in three ways: from the table of contents, by specifying a range of chapters, or by crawling from the first chapter.
The program supports customizing language and input settings, and it can generate PDF and EPUB files. The application also features a Swing interface and the ability to crawl through HTML links.
Web Book DownloaderDownload Web Book Downloader for free. Download websites as e-book: pdf, txt, epub. This application allows user to download chapters from website in 3 ways:
7- Monolith
Monolith is a CLI tool that allows you to save complete web pages as a single HTML file. It embeds CSS, image, and JavaScript assets, producing a single HTML5 document that can be stored and shared.
It also includes features like excluding audio sources, saving with custom charset, extracting contents of NOSCRIPT elements, ignoring network errors, and adjusting network request timeout.
You can install it directly using Docker locally on a remote server.
Features
- Every release contains pre-built binaries for Windows, GNU/Linux
- Exclude audio sources
- Save document using custom charset
- Extract contents of NOSCRIPT elements
- Ignore network errors
- Adjust network request timeout
8- Complete Website Downloader
This is a powerful Website downloader that seamlessly integrates with wget and archiver to efficiently download all assets of a website. It then compresses the downloaded assets and promptly sends them back to the user through a reliable socket channel.
Hazem
9- Website-cloner
The basic website cloner is a Python script that downloads all files from a website and saves them in a folder. It scrapes links on the page, saves them locally, and replaces them with the local path.
ZKAW10- Website Downloader
Website Downloader is a tool that crawls through webpages, examining and saving every link as local files. It only examines links within the same hostname and can be run with the .NET Core SDK or a compiled binary.
Kissaki11- PyWebCopy
PyWebCopy is a free tool for copying websites onto your hard-disk for offline viewing. It scans and downloads the website's content, remapping links to local paths. It can crawl an entire website and download all linked resources to create a replica of the source website.
PyWebCopy will scan the specified website and download its content onto your hard-disk. Links to resources such as style-sheets, images, and other pages in the website will automatically be remapped to match the local path. Using its extensive configuration you can define which parts of a website will be copied and how.
rajatomar78812- Crystal Web Archiver
Crystal is a web archiving tool that downloads websites for long-term preservation. It is most effective for static websites like blogs and wikis, but can also handle dynamic sites with infinite scrolling feeds, such as social media platforms.
davidfstr13- Website Downloader
This is a simple Node.js script called "Website Downloader" that can be used to download a website's source code for offline browsing.
patevs14- Website Cloner (Windows)
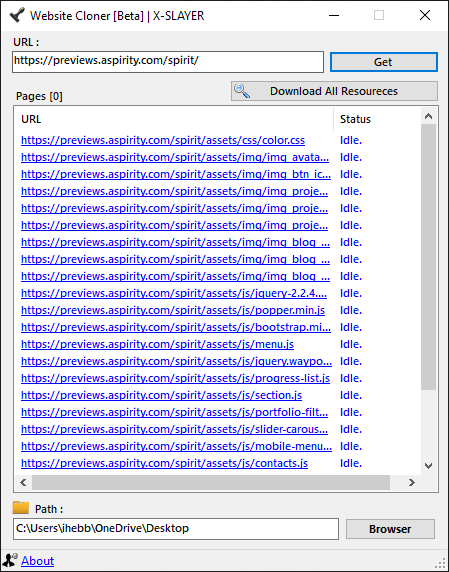
The Website Cloner is a desktop app that enables users to download website files, including HTML, CSS, JS, and images, onto their computer. It is available for Linux distributions such as Ubuntu, Debian, and Linux Mint.
15- Website-Copier PHP
Website-Copier is a PHP script that can be run on a terminal to download an entire website using link chaining. The script is available on GitHub.
sidharthasingh16- Web to PDF Converter
This script allows you to create beautiful PDFs using your favorite JavaScript and CSS framework with the Web to PDF Converter.
It fully supports JS and offers a content replacement system for dynamic content and the ability to insert page numbers dynamically.
Features
- 💥 JS is fully supported, meaning you can use your favorite frameworks to generate your PDF.
- 🔄 Comes with a powerful content replacement system that allows for dynamic content.
- 🔢 Insert page numbers in your pages dynamically.
- 💃 Full SCSS support
- 👸 Support for headers and footers
- 🔗 Support for reusable HTML chunks
- 🎥 Real time mode with hot reloading, meaning you can build your PDF in real time
- 🌏 Support for rendering remote pages (You can even inject your own css and js!)
- 🚦 Queueing system so you can render 1000's of PDFs with a single script.
PDFTron17- SingleFile (Browser Extension)
SingleFile is a fork of SingleFile that enables saving webpages as self-extracting HTML files. These files are valid ZIP files containing all the resources of the page. SingleFileZ is compatible with Firefox, Chrome, and Microsoft Edge.
gildas-lormeau18- WebimgDL
WebimgDL is a Python tool that allows you to download all images from a website. It offers features such as auto downloading, customizing image size, and customizing image width and height.
19- Sponge
Sponge is a versatile and powerful command-line tool designed for efficient website crawling and seamless link downloading.
It offers a wide range of features that make it an indispensable tool for web developers and researchers. With sponge, you can effortlessly explore and analyze websites, extract valuable data, and effortlessly download links for offline browsing.
spypunkHmza



