LaTeX-OCR: Free and Open-Source Python-based OCR for Scientific Document Conversion

Are You Truly Ready to Put Your Mobile or Web App to the Test?
Don`t just assume your app works—ensure it`s flawless, secure, and user-friendly with expert testing. 🚀
Why Third-Party Testing is Essential for Your Application and Website?We are ready to test, evaluate and report your app, ERP system, or customer/ patients workflow
With a detailed report about all findings
Contact us nowTable of Content
In academia, research, and scientific fields, LaTeX has long been the preferred markup language for creating complex mathematical formulas and professional-grade documentation.
However, converting printed or scanned documents containing LaTeX code back into an editable format can be challenging. Enter LaTeX-OCR, an open-source project designed to tackle this problem.
What is LaTeX-OCR?
LaTeX-OCR is a powerful tool that extracts LaTeX code from printed or handwritten mathematical equations. It simplifies the conversion of scanned documents or PDFs into editable LaTeX text.
Using cutting-edge optical character recognition (OCR) technology, LaTeX-OCR processes complex equations and generates precise LaTeX markup from images. This streamlines a previously time-consuming task for researchers, students, and educators.
How It Works
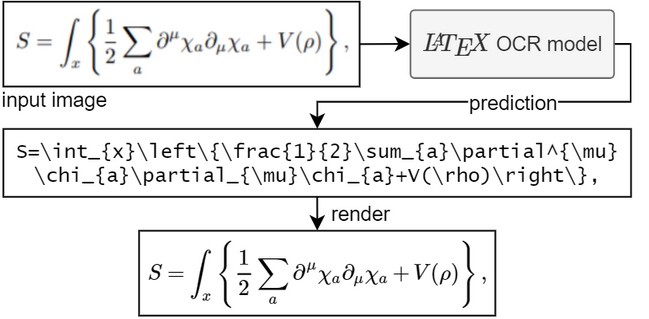
LaTeX-OCR uses advanced deep learning models to identify and interpret mathematical symbols, equations, and text from input images, converting them into LaTeX code.
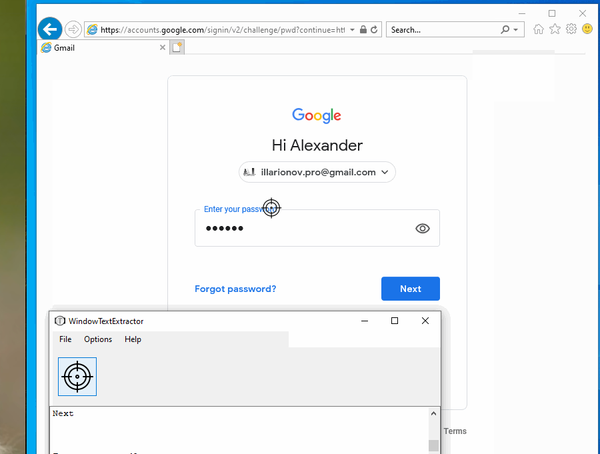
This tool streamlines the process of digitizing various sources—whether you're working with scanned papers, whiteboard photos, or handwritten formulas—making it easier to transform them into editable digital formats.
The process involves three key steps:
- Image Preprocessing: Cleaning the image to enhance OCR readability by removing noise and unnecessary details.
- Character and Symbol Recognition: Employing trained models to identify individual symbols and structures.
- LaTeX Conversion: Transforming the recognized symbols into LaTeX code, enabling users to edit and reuse the output seamlessly.
Features of LaTeX-OCR
- High Accuracy: Excellent recognition of both printed and handwritten mathematical expressions.
- Complex Formula Support: Handles intricate equations and large mathematical structures, including fractions, integrals, and summations.
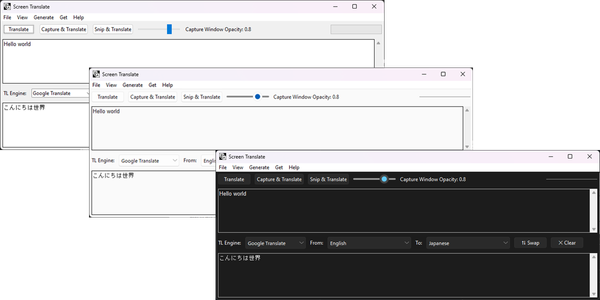
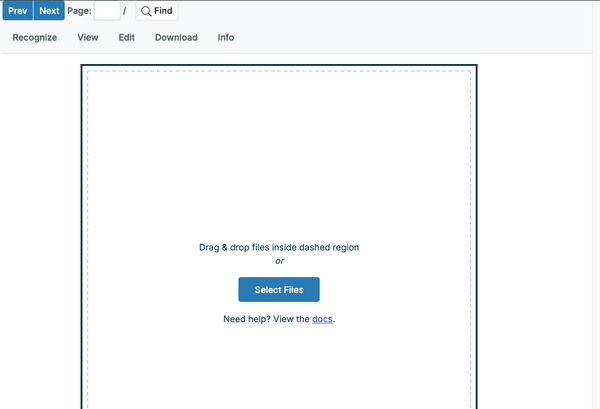
- Versatile Input Formats: Accepts scanned PDFs, images, and screenshots.
- Editable Output: Generates LaTeX code for easy export and integration into research papers, publications, or reports.
- Cross-platform Compatibility: Functions on various operating systems, ensuring wide accessibility.
- Easy to install using Python or install using Docker
Use Cases for LaTeX-OCR
- Academic Research: Transforming scanned mathematical formulas into editable LaTeX code for papers, theses, or projects.
- Education: Enabling teachers and students to convert handwritten notes into LaTeX code for digital assignments or presentations.
- Content Digitization: Assisting archivists and librarians in digitizing old mathematical texts, creating searchable LaTeX documents.
Why LaTeX-OCR is a Game-Changer
LaTeX-OCR bridges the gap between traditional printed material and the digital realm, saving countless hours of manual transcription.
Whether you're revisiting past research or collaborating on a complex project, this tool streamlines the transition from physical to digital formats.
Its ability to accurately interpret intricate mathematical structures makes it indispensable in academic and scientific communities.
Final Thoughts
LaTeX-OCR stands as an indispensable asset for those working with mathematical documents. Its remarkable accuracy and prowess in handling intricate equations dramatically streamline the process of converting printed or handwritten material into LaTeX format.
Whether you're immersed in research, shaping young minds as an educator, or pursuing academic excellence as a student, LaTeX-OCR promises to boost your productivity significantly.
For more details and to contribute, visit the LaTeX-OCR GitHub repository.
 lukas-blecher
lukas-blecher