54 Free Open-source Web Spiders, Crawlers and Scrapping Solutions for Data Collection


Web crawling, scraping, and spiders are all related to the process of extracting data from websites.
Web crawling is the process of automatically gathering data from the internet, usually with the goal of building a database of information. This is often done by searching for links within web pages, and following those links to other pages.
Web scraping is similar, but focuses on extracting specific data from websites, rather than gathering data broadly. This can be done manually or with the use of specialized software.
Spiders are a type of software used for web crawling and web scraping. They are designed to automate the process of following links and extracting data from websites.
The best use-cases for web crawling, scraping, and spiders include:
- Market research: gathering data on competitors, pricing, and industry trends.
- Lead generation: finding potential customers and their contact information.
- SEO: analyzing website structure and content to optimize search engine rankings.
- Content aggregation: gathering data from multiple sources to create a database or comparison tool.
The target audience for web crawling, scraping, and spiders varies depending on the specific use-case. However, it is typically used by businesses, marketers, and researchers who are looking to gather and analyze large amounts of data from the internet.
1- Crawlab
Crawlab is a distributed web crawler management platform is based on Golang and supports a wide range of languages, including Python, Node.js, Go, Java, and PHP. It also has the flexibility to work with various web crawler frameworks, such as Scrapy, Puppeteer, and Selenium.
It can be installed using Docker and Docker-compose in mins.
 crawlab-team
crawlab-team2- Gerapy
Gerapy is a self-hosted Distributed Crawler Management Framework Based on Scrapy, Scrapyd, Scrapyd-Client, Scrapyd-API, Django and Vue.js. It is available to install using Docker or from source.
Gerapy comes with developer-friendly documentation that allows developers to quickly start coding their scraping and crawling scenarios.
Gerapy3- Serritor (Java)
Serritor is the perfect choice for anyone looking for an open-source web crawler framework. Built upon Selenium using Java, it provides the ability to crawl dynamic web pages that require JavaScript to render data.
peterbencze4- WBot
WBot is a configurable, thread-safe web crawler, provides a minimal interface for crawling and downloading web pages.
Features
- Clean minimal API.
- Configurable: MaxDepth, MaxBodySize, Rate Limit, Parrallelism, User Agent & Proxy rotation.
- Memory-efficient, thread-safe.
- Provides built-in interface: Fetcher, Store, Queue & a Logger.
twiny5- Abot
Abot is a C# web crawler framework that handles tasks like multithreading, http requests, and link parsing. It's fast and flexible, and supports custom implementations of core interfaces. Abot Nuget package has high compatibility with many .net framework/core implementations, with version >= 2.0 targeting Dotnet Standard 2.0 and version < 2.0 targeting .NET version 4.0.
Features
- Open Source (Free for commercial and personal use)
- It's fast, really fast!!
- Easily customizable (Pluggable architecture allows you to decide what gets crawled and how)
- Heavily unit tested (High code coverage)
- Very lightweight (not over engineered)
- No out of process dependencies (no databases, no installed services, etc...)
sjdirect6- ACHE Focused Crawler
ACHE is a focused web crawler. It collects web pages that satisfy some specific criteria, e.g., pages that belong to a given domain or that contain a user-specified pattern.
ACHE differs from generic crawlers in that it uses page classifiers to distinguish between relevant and irrelevant pages in a given domain. A page classifier can be as simple as a regular expression that matches every page containing a specific word or as complex as a machine-learning based classification model.
Moreover, ACHE can automatically learn how to prioritize links to efficiently locate relevant content while avoiding the retrieval of irrelevant content.
ACHE supports many features, such as:
- Regular crawling of a fixed list of websites
- Discovery and crawling of new relevant websites through automatic link prioritization
- Configuration of different types of pages classifiers (machine-learning, regex, etc)
- Continuous re-crawling of sitemaps to discover new pages
- Indexing of crawled pages using Elasticsearch
- Web interface for searching crawled pages in real-time
- REST API and web-based user interface for crawler monitoring
- Crawling of hidden services using TOR proxies
VIDA-NYU7- crawlframej
A simple framework for a focused web-crawler in Java.
The framework has been successfully used to build a focused web-crawler for a major blogging site.
davidpasch18- Crawlee
Crawlee covers your crawling and scraping end-to-end and helps you build reliable scrapers. Fast.
Your crawlers will appear human-like and fly under the radar of modern bot protections even with the default configuration. Crawlee gives you the tools to crawl the web for links, scrape data, and store it to disk or cloud while staying configurable to suit your project's needs.
Features
- Single interface for HTTP and headless browser crawling
- Persistent queue for URLs to crawl (breadth & depth first)
- Pluggable storage of both tabular data and files
- Automatic scaling with available system resources
- Integrated proxy rotation and session management
- Lifecycles customizable with hooks
- CLI to bootstrap your projects
- Configurable routing, error handling and retries
- Dockerfiles ready to deploy
- Written in TypeScript with generics
HTTP Crawling
- Zero config HTTP2 support, even for proxies
- Automatic generation of browser-like headers
- Replication of browser TLS fingerprints
- Integrated fast HTML parsers. Cheerio and JSDOM
- Yes, you can scrape JSON APIs as well
Real Browser Crawling
- JavaScript rendering and screenshots
- Headless and headful support
- Zero-config generation of human-like fingerprints
- Automatic browser management
- Use Playwright and Puppeteer with the same interface
- Chrome, Firefox, Webkit and many others
apify9- Apache Nutch (Java)
Apache Nutch is an extensible and scalable web crawler.
apache10- Spidr (Ruby)
Spidr is a Ruby web spidering library that is capable of spidering a single site, multiple domains, specified links, or infinitely. Spidr's design prioritizes speed and ease of use.
Features:
- Follows:
a,iframe,frame, cookies protected links - Meta refresh direct support
- HTTP basic auth protected links
- Black-list or white-list URLs based upon:URL scheme, Host name, Port number, Full link, URL extension, Optional /robots.txt support.
- HTTPS support
- Custom proxy settings
postmodern11- GOPA
GOPA, is an open-source web Spider Written in Go. Its goals are focused on:
- Light weight, low footprint, memory requirement should < 100MB
- Easy to deploy, no runtime or dependency required
- Easy to use, no programming or scripts ability needed, out of box features
infinitbyte12- ant
The Go package includes functions that can scan data from the page into your structs or slice of structs, this allows you to reduce the noise and complexity in your source-code.
yields13- Scrapy (Python)

Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
scrapy14- Creeper
This is a web crawler and scraper built in Python 3.9. It works with HTTP(S) and FTP(S) links and also allows you to scrape for emails and phone numbers if desired.
z7r1k315- Python Web Crawler
This Python script can be used as a corresponding web crawler from a specific URL. This browser monitors its features while navigating on the given URL and keeps detailed logs for each URL visited.
Features
- Searches numerous HTML from a URL.
- Finds links in the explored HTML content and adds URLs to visit them.
- You can set the maximum depth level.
- Keeps a list of visited URLs and does not revisit the same URL.
- There are appropriate error message and exception handling elements for error handling.
- Uses color logging.
0MeMo0716- Colly
Colly is a scraping framework for Gophers that provides a clean interface for writing crawlers, scrapers, and spiders. It allows for easy extraction of structured data from websites, which can be used for data mining, processing, or archiving.
Features
- Clean API
- Fast (>1k request/sec on a single core)
- Manages request delays and maximum concurrency per domain
- Automatic cookie and session handling
- Sync/async/parallel scraping
- Caching
- Automatic encoding of non-unicode responses
- Robots.txt support
- Distributed scraping
- Configuration via environment variables
- Extensions
gocolly17- pyspider
pyspider is a Robust Python Spider (Web Crawler) System.
Its features include:
- Powerful WebUI with script editor, task monitor, project manager, and result viewer
- Database backend options include: MySQL, MongoDB, Redis, SQLite, and Elasticsearch; PostgreSQL with SQLAlchemy
- Message queue options include: RabbitMQ, Redis, and Kombu
- Advanced task management features such as task priority, retry, periodical, recrawl by age, etc.
- Distributed architecture, with support for Crawl Javascript pages and Python 2.{6,7}, 3.{3,4,5,6}
binux18- Katana

Katana is a powerful and versatile tool used for crawling and spidering. Its state-of-the-art framework is written entirely in Go, providing users with a seamless and efficient experience.
This tool is perfect for those looking to enhance their web scraping capabilities and gain valuable insight into their target websites. With Katana, you can easily customize the tool to fit your specific needs, allowing for a more personalized and effective approach to your web scraping endeavors.
Whether you are a seasoned professional or a beginner, Katana is an excellent choice for anyone looking to take their web scraping to the next level.
Features
- Fast And fully configurable web crawling
- Standard and Headless mode support
- JavaScript parsing / crawling
- Customizable automatic form filling
- Scope control - Preconfigured field / Regex
- Customizable output - Preconfigured fields
- INPUT - STDIN, URL and LIST
- OUTPUT - STDOUT, FILE and JSON
projectdiscovery19- Hakrawler (Go)
Hakrawler is a fast Golang web crawler that gathers URLs and JavaScript file locations. It is a simple implementation of the awesome Gocolly library.
hakluke20- Scrapyteer (Browser + Node.js)
Scrapyteer is a Node.js web scraping tool that uses Puppeteer to scrape both plain HTML pages and JavaScript-generated content, including SPAs. It offers a small set of functions to define a crawling workflow and output data shape.
miroshnikov21- Kankra (Python)
Kankra is an open-source free Website Spider/Crawler, written in Python 3.0.
Kankra features include:
- Crawls a website for hrefs, js & img files
- Detects links that use a full URL and those without
-> e.g<a href="https://www.ssllabs.com/index.html"VS<a href="/projects/index.html - Adjusts the results for a useful output
- Removes duplicates
- Automatic out of Scope checking
- Configurable:
Ak-wa22- DirFinder
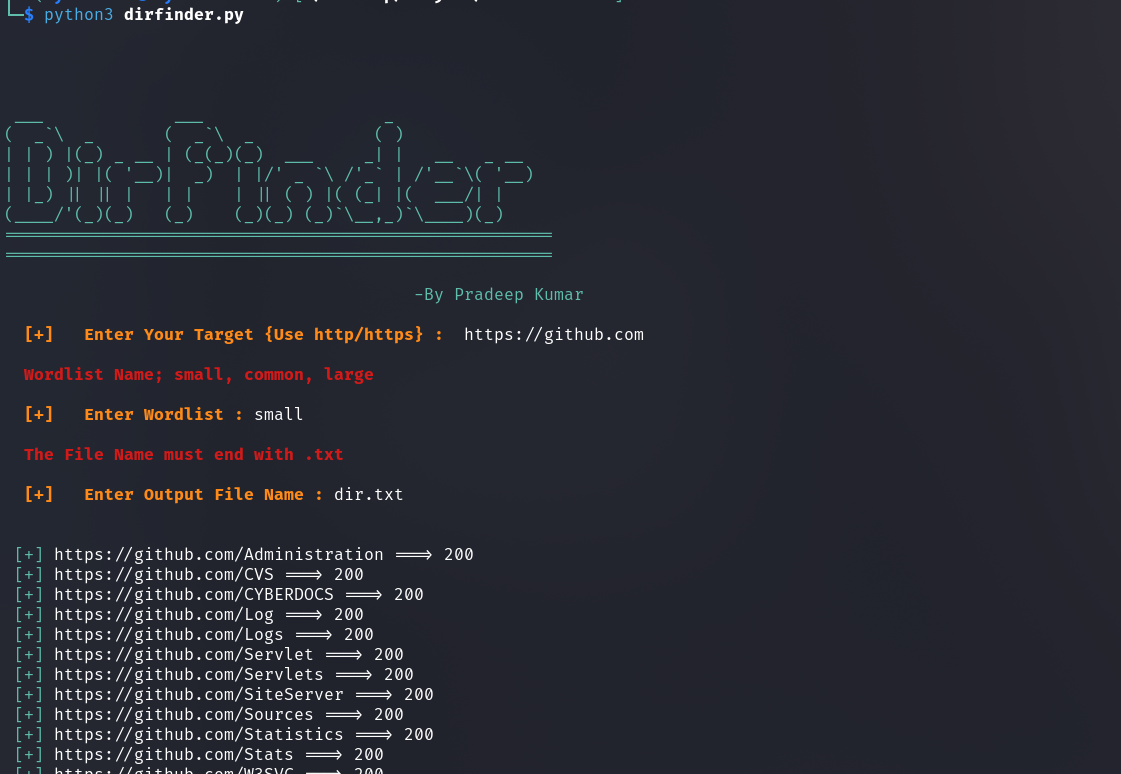
The DirFinder tool is user for bruteforce directory with dedicated Wordlist is very simple user-friendly to use. It is written in Python.
Features
- Multi-threading on demand
- Supports php, asp and html extensions
- Four different types of wordlist
- Checks for potential EAR vulnerabilites
- user-friendly
CyberPlatoon23- Bose Framework
✨ Bose is a a feature-rich Python framework for Web Scraping and Bot Development. 🤖
omkarcloud24- Web Crawler (Jupyter Notebook)
This is a web crawling program which can connect a specific website and crawl the main content (data) of that website.
Once you know the main content of the website, it is good to know the type of website and categorize it.
Therefore, an algorithm is proposed which crawls a specific website using this program and determines the similarity between two websites according to the data contained in the website.
EunBinChoi25- AutoScraper
AutoScraper is an excellent tool for Python developers looking to extract specific data from web pages. With its Smart, Automatic, Fast, and Lightweight features, it can easily retrieve URLs or HTML content and extract a wide range of data types, including text, URLs, and any HTML tag value from a page.
In addition to its web scraping capabilities, AutoScraper can learn the scraping rules and return similar elements, allowing developers to use the learned object with new URLs to extract similar content or exact elements from those pages. With its powerful capabilities and ease of use, AutoScraper is an essential tool for anyone looking to extract valuable information from the web.
alirezamika26- Ferret
Ferret is a web scraping system that simplifies data extraction from the web for various purposes, including UI testing, machine learning, and analytics. It uses a declarative language to abstract away technical details and is portable, extensible, and fast.
Features
- Declarative language
- Support of both static and dynamic web pages
- Embeddable
- Extensible
alirezamika27- DotnetSpider
DotnetSpider, is a .NET Standard web crawling library. It is a lightweight, efficient, and fast high-level web crawling & scraping framework.
dotnetcore28- crawlergo
Crawlergo is a browser crawler that uses Chrome headless mode for URL collection, automatically filling and submitting forms and collecting as many entries as possible. It includes a URL de-duplication module and maintains fast parsing and crawling speed for large websites to get high-quality collection of request results.
Features
- chrome browser environment rendering
- Intelligent form filling, automated submission
- Full DOM event collection with automated triggering
- Smart URL de-duplication to remove most duplicate requests
- Intelligent analysis of web pages and collection of URLs, including javascript file content, page comments, robots.txt files and automatic Fuzz of common paths
- Support Host binding, automatically fix and add Referer
- Support browser request proxy
- Support pushing the results to passive web vulnerability scanners
Qianlitp29- Grab Framework Project
Grab is a free open-source Python-based library for website scrapping.
lorien30- Geziyor
Geziyor is a blazing fast web crawling and web scraping framework. It can be used to crawl websites and extract structured data from them. Geziyor is useful for a wide range of purposes such as data mining, monitoring and automated testing.
Features
- JS Rendering
- 5.000+ Requests/Sec
- Caching (Memory/Disk/LevelDB)
- Automatic Data Exporting (JSON, CSV, or custom)
- Metrics (Prometheus, Expvar, or custom)
- Limit Concurrency (Global/Per Domain)
- Request Delays (Constant/Randomized)
- Cookies, Middlewares, robots.txt
- Automatic response decoding to UTF-8
- Proxy management (Single, Round-Robin, Custom)
geziyor31- FEAPDER (Python)
feapder is an easy to use, powerful crawler framework
Boris-code32- Trafilatura
Trafilatura is a Python package and command-line tool for web crawling, downloads, scraping, and extraction of main texts, metadata, and comments. It aims to eliminate noise caused by recurring elements and includes author and date information. It is useful for quantitative research in corpus linguistics, natural language processing, and computational social science, among others.
Features
- Web crawling
- Text discovery
- Sitemap support
- Seamless and parallel processing, online and offline
- Robust and efficient extraction
- Output formats: Text, CSV, JSON, XML
- Optional add-ons.
- Trafilatura is distributed under the GNU General Public License v3.0.
adbar33- Infinity Crawler
Infinity Crawler is a simple but powerful web crawler library for .NET.
The crawler is built around fast but "polite" crawling of website. This is accomplished through a number of settings that allow adjustments of delays and throttles.
You can control:
- Number of simulatenous requests
- The delay between requests starting (Note: If a
crawl-delayis defined for the User-agent, that will be the minimum) - Artificial "jitter" in request delays (requests seem less "robotic")
- Timeout for a request before throttling will apply for new requests
- Throttling request backoff: The amount of time added to the delay to throttle requests (this is cumulative)
- Minimum number of requests under the throttle timeout before the throttle is gradually removed
Features:
- Obeys robots.txt (crawl delay & allow/disallow)
- Obeys in-page robots rules (
X-Robots-Tagheader and<meta name="robots" />tag) - Uses sitemap.xml to seed the initial crawl of the site
- Built around a parallel task
async/awaitsystem - Swappable request and content processors, allowing greater customisation
- Auto-throttling (see below)
TurnerSoftware34- SpiderX
This is a simple web-crawler development framework based on .Net Core.
LeaFrock35- Onion-Crawler
C# based Tor/Onion Web crawler. There might be some errors/bugs so, feel free to contribute and mess with my code.
OzelTam36- Webcrawler
Web Crawler , that crawls all the inner links and the process goes on till no link is left and ignoring repeatedly crawled links
Open Ipython Console and run the below command to see the extracted URL’s: python sitemapcrawl.py.
mounicmadiraju37- GoTor
This repository contains an HTTP REST API and a command-line program designed for efficient data gathering and analysis through web crawling using the TOR network. While the program is primarily designed to work seamlessly with TorBot, the API and CLI can also operate independently.
DedSecInside38- Spidey
Spidey is a multi threaded web crawler library that is generic enough to allow different engines to be swapped in.
JaCraig39- Mimo Crawler (JavaScript)
Mimo is a web crawler that uses non-headless Firefox and js injection to crawl webpages. It uses websockets to communicate between a non-headless browser and the client, allowing for interaction and crawling of webpages by evaluating javascript code into the page's context.
Features
- Simple Client API
- Interactive crawling
- Extremely fast compared to similar tools.
- Fully operated by your javascript code
- Web spidering
NikosRig40- WebReaper
WebReaper is a declarative high performance web scraper, crawler and parser in C#. Designed as simple, extensible and scalable web scraping solution. Easily crawl any web site and parse the data, save structed result to a file, DB, or pretty much to anywhere you want.
pavlovtech41- Qaahl
Qaahl a simple webcrawler that can generate a graphical view of the crawled path.
surbhitt42- Web Wanderer (Python)
Web Wanderer is a Python-based web crawler that uses concurrent.futures. ThreadPoolExecutor and Playwright to crawl and download web pages. It is designed to handle dynamically rendered websites and can extract content from modern web applications.
biraj2143- Scrapio
Asyncio web scraping framework. The project aims to make easy to write a high performance crawlers with little knowledge of asyncio, while giving enough flexibility so that users can customise behaviour of their scrapers. It also supports Uvloop, and can be used in conjunction with custom clients allowing for browser based rendering.
EdmundMartin44- CobWeb
This is a project carried out for the collection of climatic data, as well as data on bugs and diseases that affect crops in agriculture.
Lucs159045- Spring Boot Web Crawler and Search Engine
This project provides a REST API that allows users to submit URLs for crawling. The app internally uses RabbitMQ to publish the URLs, and then listens back to fetch the contents of the URLs using Jsoup.
The app also scrapes links and indexes the content using Apache Lucene. Finally, the app recursively publishes the links to RabbitMQ.
deviknitkkr46- uSearch (Go)
uSearch is an open-source website crawler, indexer and text search engine.
mycok47- Dolors
Dolors is a Java-based web scraper with built in web crawler that allows you to index a website and its contents including media and text related information and store the output in SQL database or just export the data into a text file for quick processing.
48- Webash
Webash serves as a scanning tool for web-based applications, primarily utilized in bug bounty programs and penetration testing. Its framework-like design allows effortless integration of vulnerability detection scripts.
49- CryCrawler
CryCrawler is a portable cross-platform web crawler. Used to crawl websites and download files that match specified criteria.
Features
- Portable - Single executable file you can run anywhere without any extra requirements
- Cross-platform - Works on Windows/Linux/OSX and other platforms supported by NET Core
- Multi-threaded - Single crawler can use as many threads as specified by the user for crawling.
- Distributed - Connect multiple crawlers to a host; or connect multiple hosts to a master host. (using SSL)
- Extensible - Extend CryCrawler's functionality by using plugins/extensions.
- Web GUI - Check status, change configuration, start/stop program, all through your browser - remotely.
- Breadth/Depth-first crawling - Two different modes for crawling websites (FIFO or LIFO for storing URLs)
- Robots Exclusion Standard - Option for crawler to respect or ignore 'robots.txt' provided by websites
- Custom User-Agent - User can provide a custom user-agent for crawler to use when getting websites.
- File Critera Configuration - Decide which files to download based on extension, media type, file size, filename or URL.
- Domain Whitelist/Blacklist - Force crawler to stay only on certain domains or simply blaclist domains you don't need.
- Duplicate file detection - Files with same names are compared using MD5 checksums to ensure no duplicates.
- Persistent - CryCrawler will keep retrying to crawl failed URLs until they are crawled (up to a certain time limit)
CryShana50- Catch
Catch is a Web crawler with built in parsers using latest Python technologies.
umrashrf51- WebCrawler
A JavaScript web-based crawler that works well with website internal links.
a29g52- Google Parser
Google parser is a lightweight yet powerful HTTP client based Google Search Result scraper/parser with the purpose of sending browser-like requests out of the box. This is very essential in the web scraping industry to blend in with the website traffic.
Features:
- Proxy support
- Custom headers support
nrjdalal53- Senginta.js Search Engine Scrapper
Senginta is a versatile search engine scraper that can extract results from any search engine and convert them to JSON. Currently, it supports Google Product Search Engine and Baidu Search Engine, but the developer welcomes contributions to support other search engines.
michael-act54- SERPMaster
SERPMaster is a SERP scraping tool that utilizes multiple Google APIs to acquire large volumes of data from Google Search Result Pages, including rich results for both paid and organic search data.SERPMaster is a scraping tool that delivers real-time data from Google Search Engine Result Pages.
Features
- 100% success rate
- Device and browser-specific requests
- City, country, or coordinate-level data
- Data in CSV, JSON, and HTML
- CAPTHAs, retries, proxy management are taken care of
- JavaScript rendering
- Python, JavaScript, PHP languages
serp-master