Meet Qwen3-VL: The Future of Vision-Language AI Is Here (And It’s Mind-Blowing)


If you’ve been keeping up with the latest in AI, you’ve probably heard whispers about Qwen3-VL, but let me be clear: this isn’t just another upgrade. This is a game-changer in multimodal intelligence.
Imagine an AI that doesn’t just see an image, it understands it like a human, parses complex documents like a pro, and even helps you code from a screenshot. That’s not sci-fi. That’s Qwen3-VL, the most powerful vision-language model (VLM) in the Qwen series to date.
What is Qwen3-VL-235B-A22B?
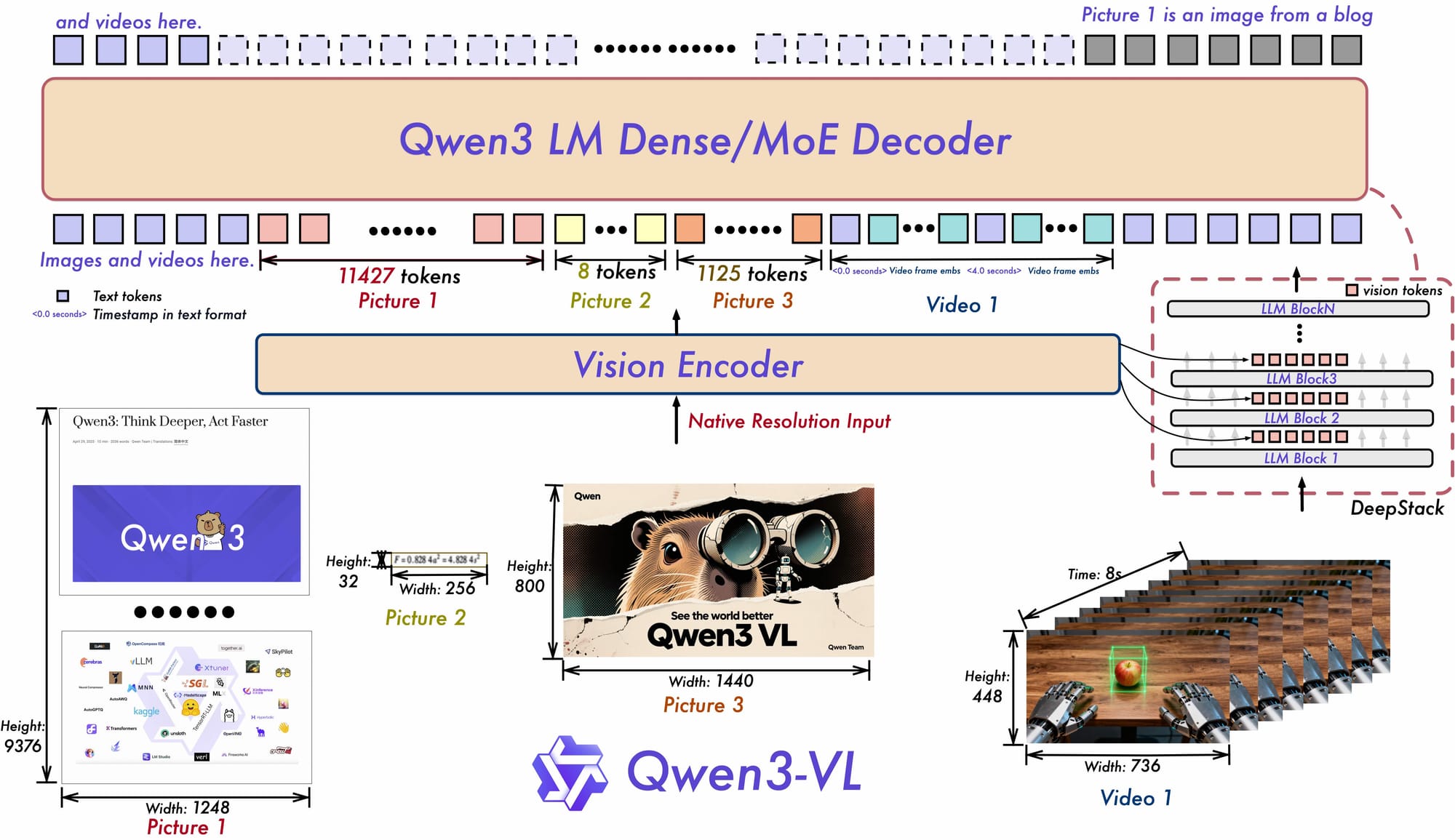
Introducing Qwen3-VL-235B-A22B, the most advanced open-source vision-language model to date. Built with a Mixture-of-Experts (MoE) architecture, it delivers unmatched performance in visual perception, spatial reasoning, long-context understanding (up to 1M tokens), and multimodal task execution.
Key upgrades include Interleaved-MRoPE for enhanced video comprehension, DeepStack for multi-layer visual feature fusion, and a text-timestamp alignment mechanism for precise temporal reasoning.
The model excels in 2D/3D grounding, document parsing, OCR across 32 languages, visual coding (HTML/CSS/JS from images), and agent-level GUI interaction. With top-tier results on benchmarks like OS World and MathVision, Qwen3-VL sets new standards in AI cognition—transforming how machines “see,” reason, and act.
Available via API, it’s ideal for developers building intelligent agents, robotics, and next-gen multimodal applications
Why Qwen3-VL Stands Out
The team at Alibaba has done it again. With Qwen3-VL, they’ve delivered a massive leap forward across every dimension:
- Text + Vision Fusion, Reads text and interprets visuals seamlessly. No more fragmented understanding.
- 256K Context (Yes, Really!): Read entire books or analyze hours-long videos with full recall.
- Advanced Spatial Reasoning: Knows where objects are, how they’re positioned, and even what’s hidden behind them.
- Visual Agent Power: Can navigate PC/mobile UIs, click buttons, fill forms, and automate tasks, all by "seeing" the screen.
- Visual Coding Boost: Turn a wireframe or app screenshot into clean Draw.io diagrams, HTML, CSS, or JavaScript.
- OCR Like No Other: Supports 32 languages, handles blurry, tilted, or low-light images with precision. Even ancient scripts? Covered.
And yes, it's open-source. Free. Powerful. Built for developers, researchers, and builders who want real-world impact.
Introducing the Qwen VLM Cookbook: Your New AI Playbook
Alibaba didn’t stop at releasing a model, they dropped a complete, practical guide: the Qwen VLM Cookbook 🎯
This isn’t just documentation. It’s a hands-on manual for unlocking the full potential of Qwen3-VL. Whether you're:
- Parsing complex invoices,
- Building AI agents that interact with apps,
- Creating automated workflows from screenshots,
- Or extracting data from long-form PDFs,
…this cookbook shows you exactly how.
Think of it as the “MIT of Multimodal AI”, packed with real examples, clear code snippets, and battle-tested use cases.
Behind the Tech: What Makes It So Smart?
Qwen3-VL-235B-A22B (the MoE version) uses a Mixture-of-Experts architecture. That means only 22 billion parameters are activated per task — out of 235 billion total.
Result? Massive power without massive cost.
It’s efficient, scalable, and perfect for everything from edge devices to cloud-scale deployments.
Who Should Care?
- Developers building AI-powered tools or agents
- Researchers exploring visual reasoning & embodied AI
- Product teams automating workflows using visual input
- Data scientists extracting meaning from images and documents
- Anyone tired of AI that can’t really see
Ready to Dive In?
Don’t just hear about the future, build it. It’s free. It’s open. And it’s already changing how people interact with AI.
Final Thought
Qwen3-VL isn’t just a model. It’s a new way of working, where your AI understands context, space, language, and action, all at once.
The age of passive vision models is over.
Welcome to the era of active, intelligent perception.
Go build something amazing.
And if you do, tag us. We’d love to see what you create.




