Scribe OCR - Free Web OCR That you can Self-host

Table of Content
Scribe OCR is a free, web-based application designed to help you extract text from images, proofread OCR data, and create fully digital documents. Whether you’re dealing with scanned PDFs, books, or any other document, Scribe OCR makes the process smoother and more accurate.
You can try it out live at scribeocr.com.
Enhance Document OCR with LLMs: 14 Open-Source Free Tools
OCR Evolution: Adding Language Models to Text Recognition
 Hazem Abbas
Hazem Abbas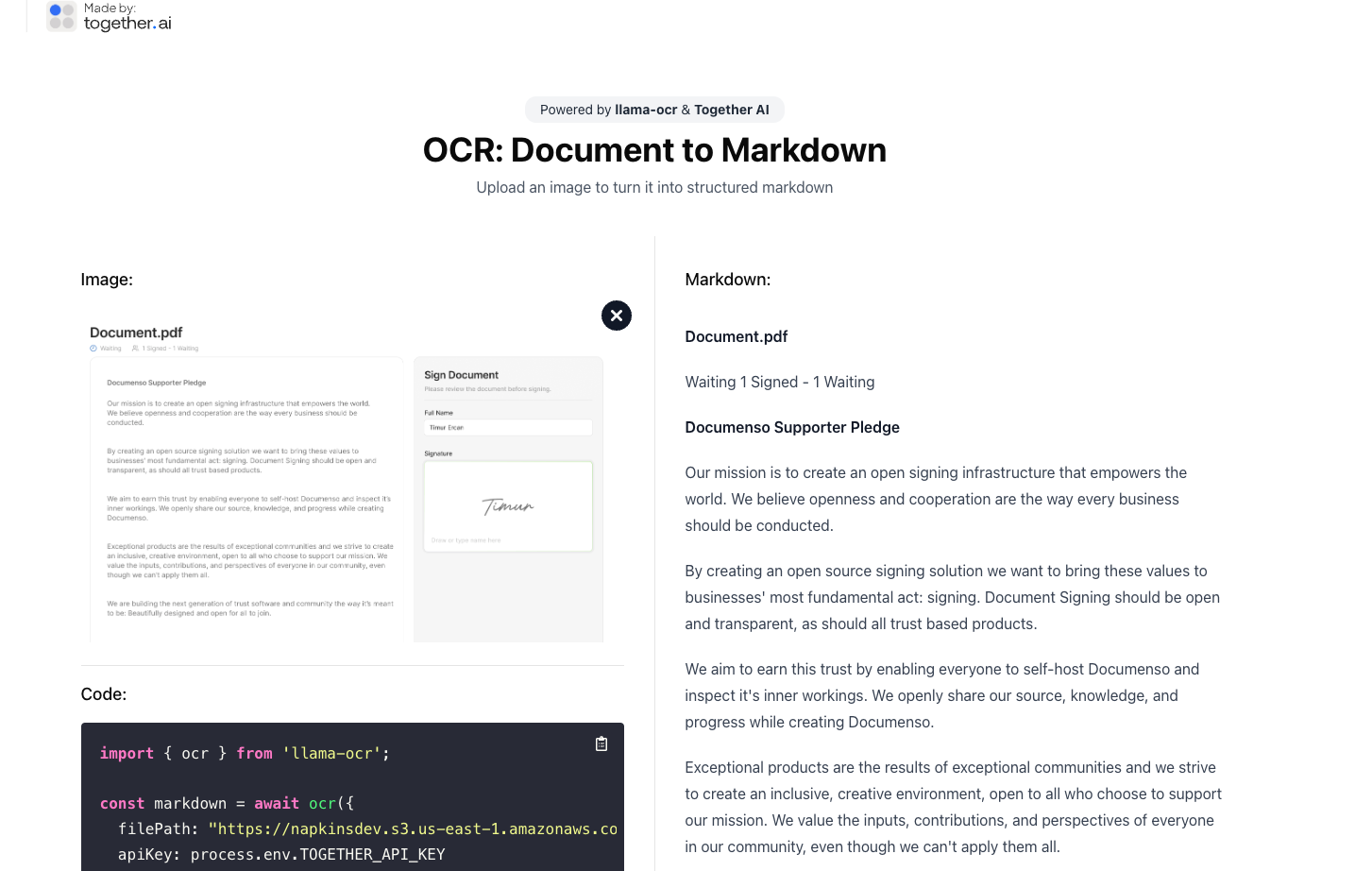
What Can You Do with Scribe OCR?
Scribe OCR is built for three main tasks:
- Add Searchable Text Layers to PDFs
If you’ve used tools like Adobe Acrobat to recognize text in a PDF, you know it can be frustrating when errors sneak in. Scribe OCR lets you easily correct those mistakes, ensuring your PDFs have accurate, searchable text layers. It’s an easy-to-use alternative that puts control back in your hands. - Proofread Existing OCR Data
Got OCR data from another tool, like Tesseract or Abbyy, that needs cleaning up? Scribe OCR makes proofreading a breeze. By accurately aligning text with the original image, you can quickly spot and correct errors—much faster than with traditional methods. - Create Fully Digital Documents and Books
Unlike many OCR tools that simply layer roughly-positioned invisible text over images, Scribe OCR goes a step further. It allows you to create true digital versions of documents—text-native, ebook-style PDFs that mirror the original layout perfectly.
Install and Run
There is currently no standalone desktop application, so running locally requires serving the files over a local HTTP server. To run a local copy, run the following commands (requires npm):
git clone --recursive https://github.com/scribeocr/scribeocr.git
cd scribeocr
npm i
npx http-serverLicense
AGPL-3.0 License
Resources & Downloads
GitHub - scribeocr/scribeocr: Web interface for recognizing text, proofreading OCR, and creating fully-digitized documents.
Web interface for recognizing text, proofreading OCR, and creating fully-digitized documents. - GitHub - scribeocr/scribeocr: Web interface for recognizing text, proofreading OCR, and creating ful…
 scribeocr
scribeocrNeed More Open-source Free OCR Tools?
OCRmyPDF: OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched (Free software)
OCRmyPDF is a free open-source command-line tool that adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. It is already being used to scan and search millions of heavy PDF files. Features Its features include: * Generates a searchable PDF/A file from a
Hazem Abbas
LaTeX-OCR: Free and Open-Source Python-based OCR for Scientific Document Conversion
In academia, research, and scientific fields, LaTeX has long been the preferred markup language for creating complex mathematical formulas and professional-grade documentation. However, converting printed or scanned documents containing LaTeX code back into an editable format can be challenging. Enter LaTeX-OCR, an open-source project designed to tackle this problem. What
Hazem Abbas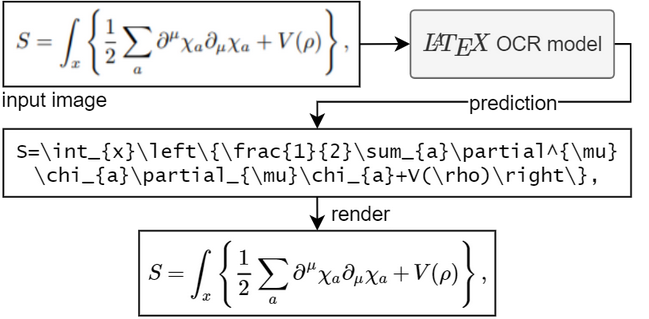
12 Top Free OCR Screen Capture Tools that Grab Text Directly from Your Screen
Screenshot OCR is a technology that allows users to extract text from screenshots and convert it into editable text. There are various screenshots to image OCR tools available that utilize Optical Character Recognition (OCR) algorithms to recognize and extract text from images of screenshots. These tools are useful in several
Hazem Abbas
12 Free OCR Libraries and Projects
What is OCR (Optical Character Recognition)? OCR or Optical Character Recognition is a process that converts images that contains text into readable editable text formats which you can edit, copy, paste and save. It is not a new technology, as it was created decades ago to aid enterprise transform their
Hazem Abbas
Web-based OCR app for Firefox and the Web
OCR for Browser is a free extension that uses ocrad.js for optical character recognition in Firefox and PC browsers. It allows you to extract text from various image formats such as JPG, GIF, TIFF, BMP, and PNG. Features * Utilize optical character recognition (OCR) technology to extract text from images
Hazem Abbas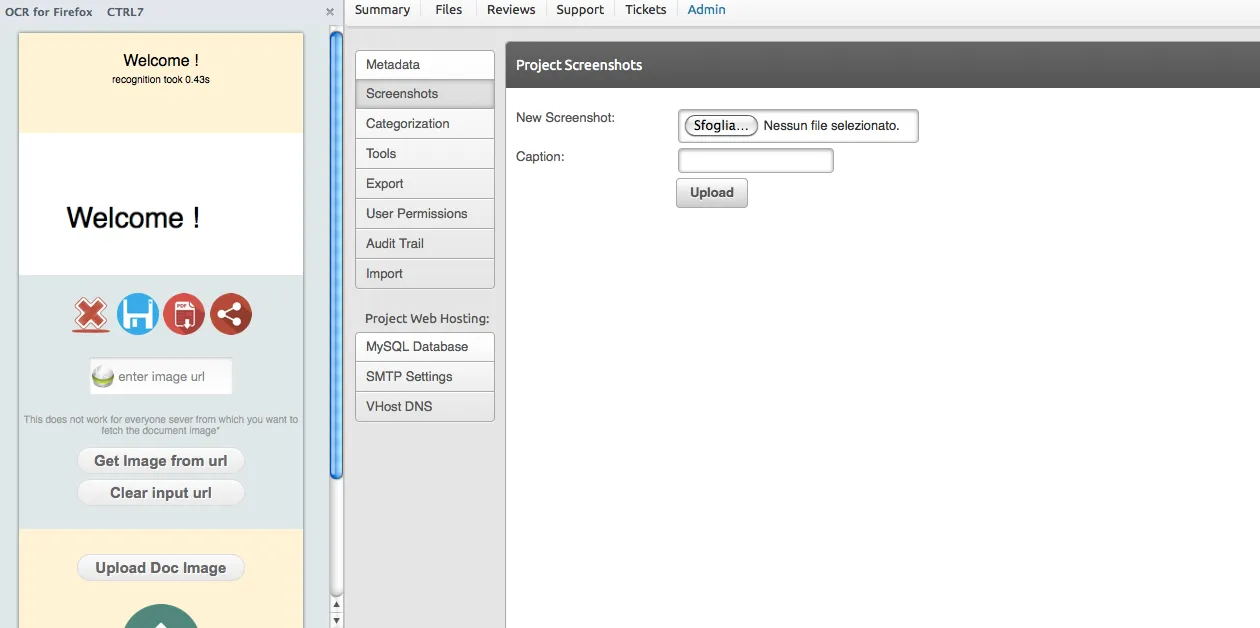
18 Open-source Free OCR for Windows
OCR (Optical Character Recognition) is a technology that allows computers to recognize text in images or scanned documents and convert it to editable text. OCR tools are commonly used in various industries, including: * Digitization of printed materials: OCR can be used to convert physical books, magazines, and newspapers into digital
Hazem Abbas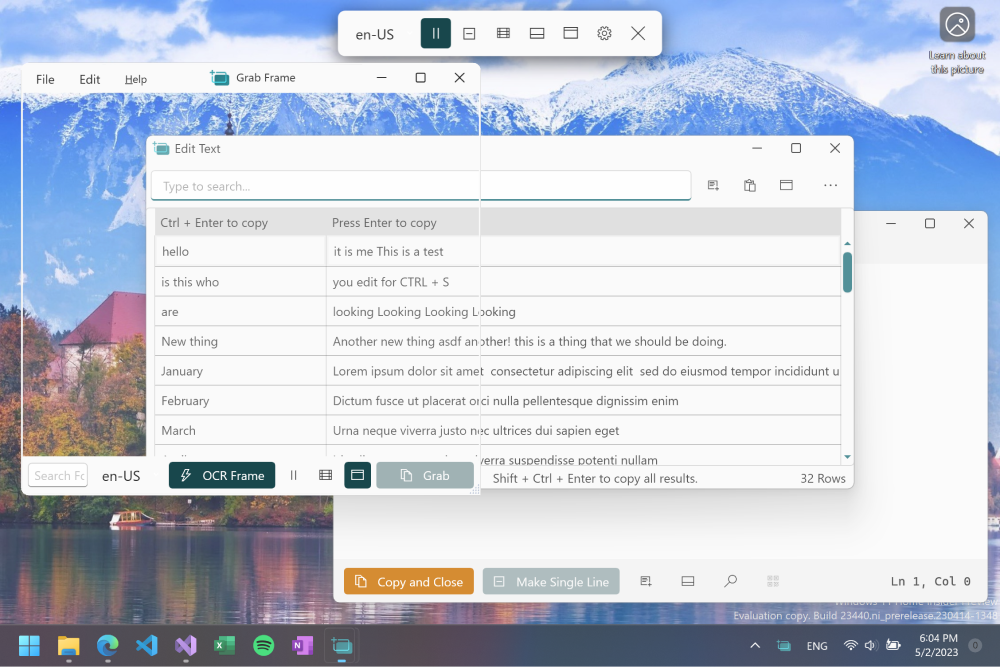
Best 9 Commercial PDF Editors with OCR support for Windows Power Users, Choose the Best one
PDF editors have become indispensable tools for professionals navigating the complex landscape of digital documentation. These software solutions empower users to manipulate, enhance, and collaborate on PDF files with unprecedented ease and efficiency. As there are many free alternatives may suffice for basic tasks, commercial PDF editors offer a comprehensive
Hazem Abbas
13 Best Open Source Free PDF OCR Text Extractors
PDF file formats are a compact format widely used to create portable documents, reports, e-books, and more. Originally developed by Adobe in 1992, it has become a world standard. PDF files can contain text, images, and tables, and can be generated by many office suites, document editors, apps, web services,
Hazem Abbas
Transform Your Documents Securely with PD3F.com - The Free Self-hosted PDF OCR Text Extractor
PD3F.com: Where privacy meets simplicity in PDF conversion 🌟
Hazem Abbas