18 Open-source Free OCR for Windows

OCR (Optical Character Recognition) is a technology that allows computers to recognize text in images or scanned documents and convert it to editable text.
OCR tools are commonly used in various industries, including:
- Digitization of printed materials: OCR can be used to convert physical books, magazines, and newspapers into digital formats that can be easily searched and shared.
- Document management: OCR can be used to extract data from documents, making it easier to organize and search through large amounts of information.
- Accessibility: OCR can be used to convert printed materials into formats that are accessible to people with visual impairments.
- Translation: OCR can be used to extract text from documents in one language and translate it into another.
There are many OCR tools available, each with its own unique features and use-cases. Some tools are designed for specific tasks, such as TessStudio for reviewing and correcting OCR data, while others like EasyOCR are more general purpose.
In this post, we will find the best free and open-source OCR tools, that you can download, install, and use for Windows, and other platforms.
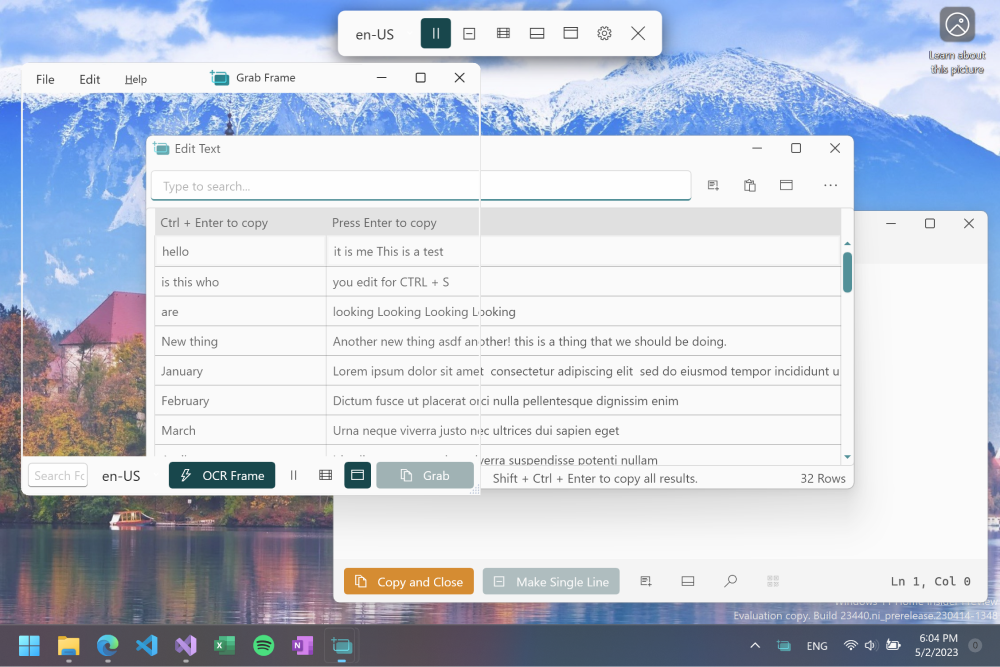
1- Text-Grab
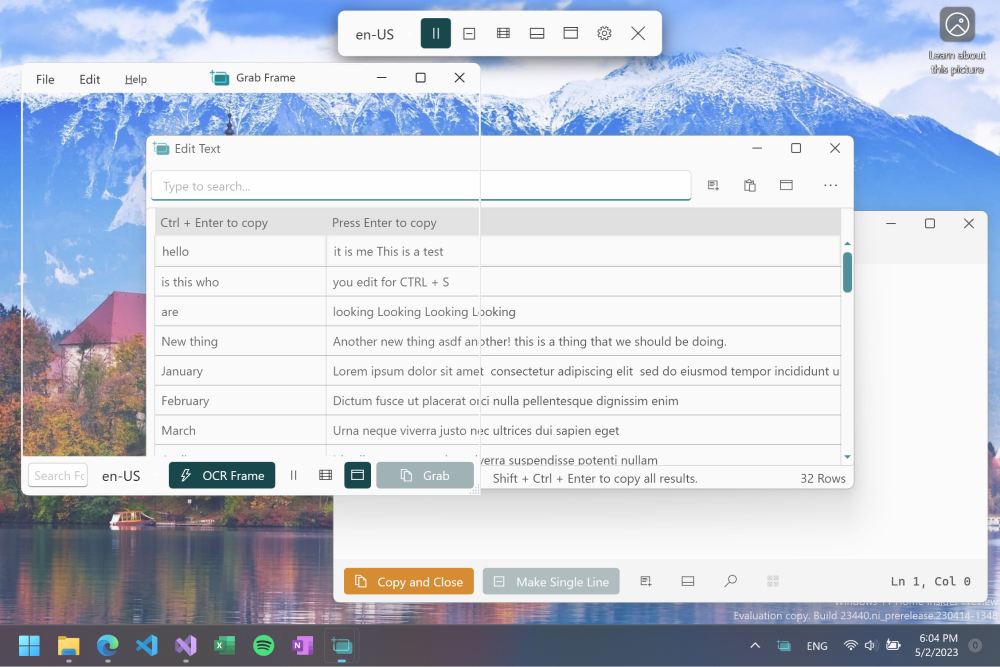
Text-Grab is a Windows 10/11 OCR utility that takes a screenshot, passes the image to the local Windows API OCR engine, and puts the text into the clipboard for use anywhere. It has different modes to make working with text fast and easy.
 TheJoeFin
TheJoeFin2- OCR Translator
OCR Translator enables you to effortlessly convert captured images into text, and confidently translate that text with ease.
Features
- Desktop application with a user-friendly graphical user interface (GUI) provided by customtkinter.
- Ability to select preferred OCR and translation services.
- Option to run the program using either the START button or the keyboard shortcut (Alt+Win+T or bound from options).
- Capability to choose the area of the screen to scan for text using OCR and save the position (for example, when watching a movie and the subtitles always appear in one spot, so you don't have to select the text area again).
- Automatic translation of the captured text if a translation service has been selected.
- Ability to capture subtitles from movies or games by selecting the corresponding area of the screen and displaying the translated text next to them.
- Chat with chatGPT or edgeGPT.
- Ability to translate from the clipboard or manually entered text (similar to a typical translation app).
- Save all selected options and settings to a file and load them when the program is launched.
Azornes3- TessStudio

TessStudio is a powerful Windows program designed for creating, reviewing, and correcting OCR data in searchable PDF files using the highly reliable Tesseract engine.
Features
- Supports image and multipage PDF files, with or without prior OCR data.
- Can run or re-run the Tesseract OCR process the current page, all pages or selected pages.
- Preserves any visible text on a PDF page while performing OCR on the image elements only.
- For multipage files, multiple instances of the tesseract engine run in parallel for improved performance. The speed improvement depends on the number of processor cores.
- Identify and display OCR text at the word level with detected word boundaries visible.
- The built-in spell checker automatically tags words not found in the dictionary.
- Display PDF pages in the following modes: Image with OCR text hidden, OCR text visible and image hidden, and OCR text visible on faded image.
- Use any installed font to display OCR text. Fonts are automatically scaled to fit word boundaries.
- Click on a visible word to open a text editor to correct OCR mistakes.
- Split a selected word at the current cursor position into two words, or merge the selected word with the next word.
- Modify or move word boundaries.
- Create new OCR words, delete existing words.
- Supports any number of Undo and Redo operations.
- Save corrections as searchable PDF files. Optionally save as PDF/A or encrypted PDF files.
- Experimental support for removing grid lines and handling a mixed-mode page with both light text on dark background and dark text on light background. This is common with table headers.
- Capture and examine debug intermediary images and OCR output in text.
OpaitSoftware4- ImageScanOCR
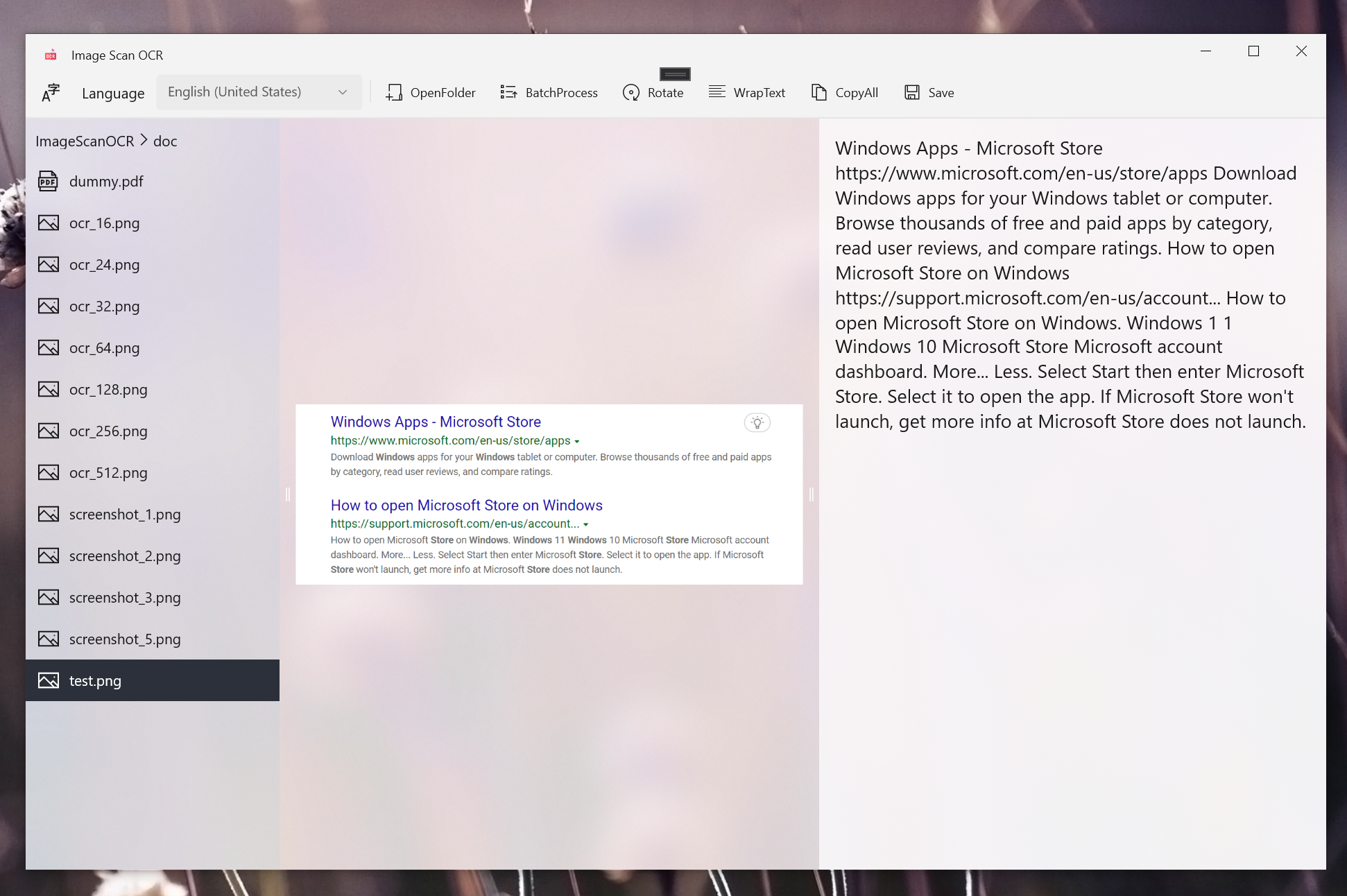
Image Scan OCR is the ultimate tool for recognizing text from images and PDFs using Windows OCR. With this powerful OCR app, you can easily convert any text image to editable plain text.
And the best part? You can easily manage and save the OCR result text as a plain text file, making it simple to organize and access your important information.
ttop325- EasyOCR

EasyOCR is an OCR software that is ready to use and supports over 80 languages, including popular writing scripts such as Latin, Chinese, Arabic, Devanagari, Cyrillic, and more.
 Hamza Mousa
Hamza Mousa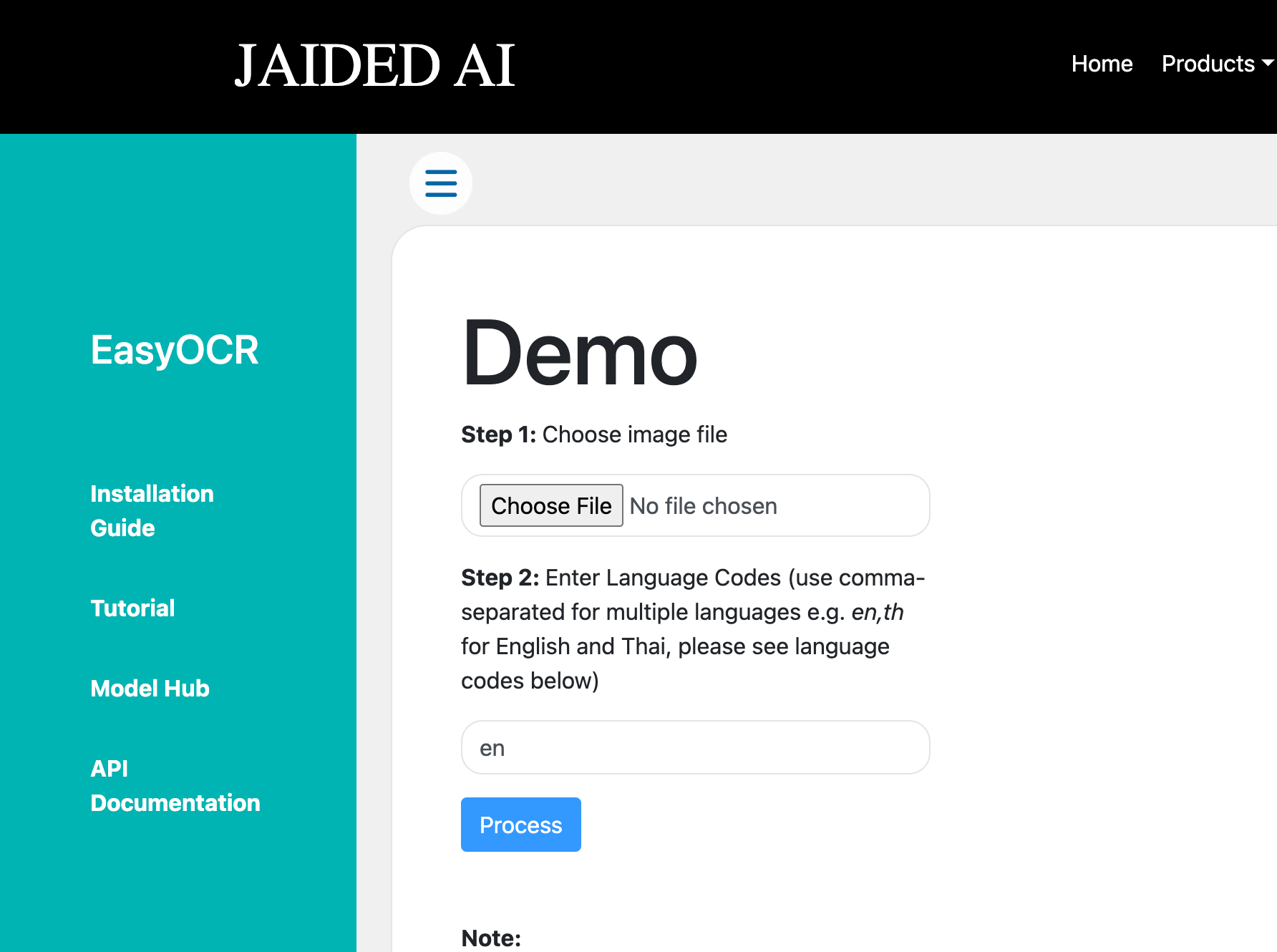 JaidedAI
JaidedAI6- (a9t9) Free OCR Software
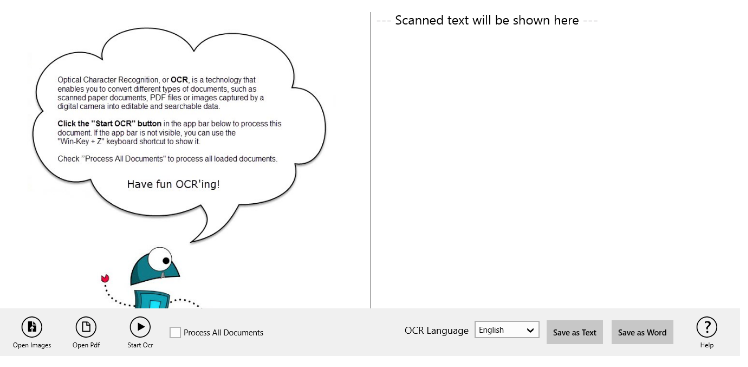
This is a Free open-source OCR application for the Windows Store - A modern GUI front-end for the Microsoft OCR library. The application also includes support for reading and OCR'ing PDF files.
A9T97- pdf2pdfocr
This is an exceptional tool that swiftly OCRs PDFs (and supported images) with the added feature of appending a text "layer" to the original file, transforming it into a highly searchable PDF.
The script exclusively employs open source tools, solidifying its status as a reliable asset.
LeoFCardoso8- Cuneiform-OCR (Python)
This repository contains code for line detection, character detection and recognition on the cuneiform 2d images.
Each folder contains the respective code for:
- Line Detection: Using Image processing techniques, line indentations are found on Cuneiform rgb images.
- Object Detection: Using maskrcnn Cuneiform characters and line indentations are found on Cuneiform rgb images.
- Synthetic: To create synthetic cuneiform rgb images with annotations for maskrcnn training.
cdli-gh9- NormCap
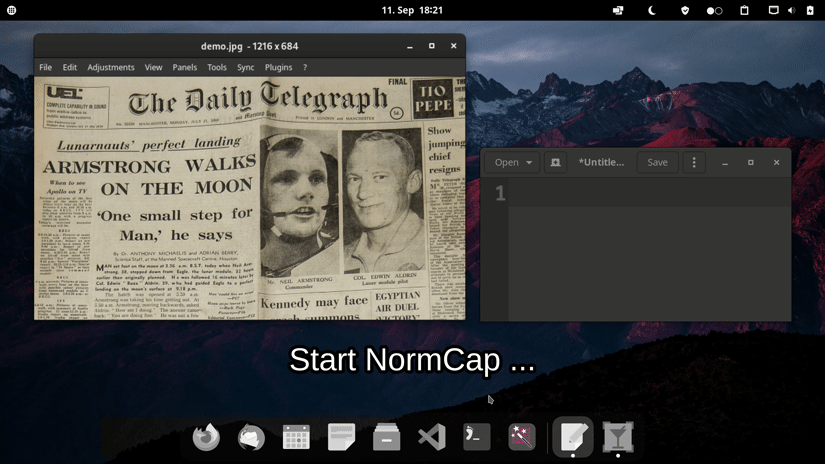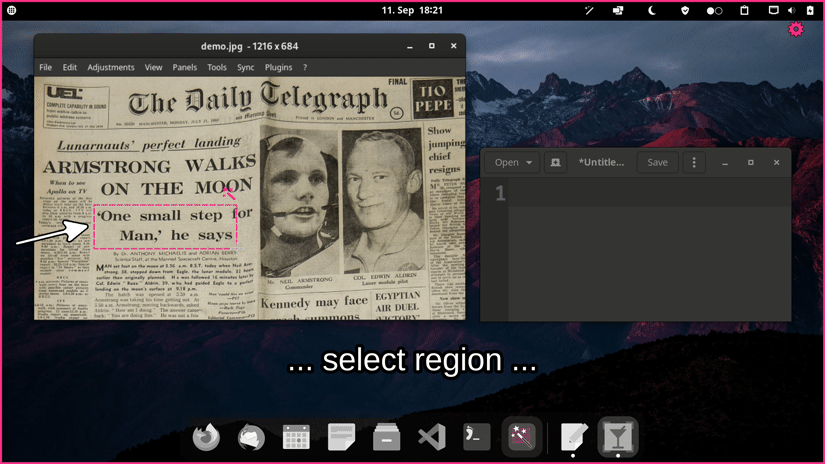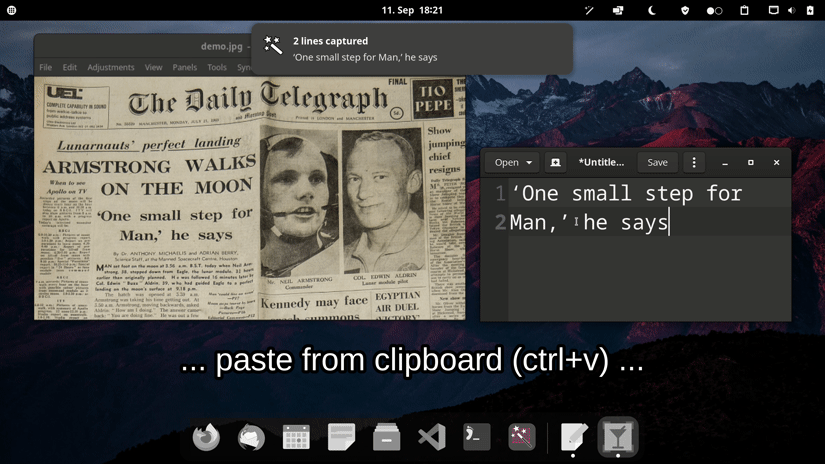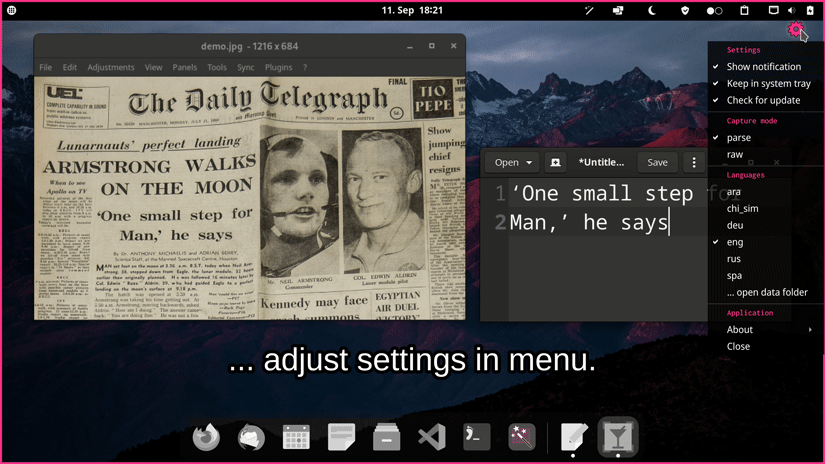
Our OCR-powered screen-capture tool captures information more efficiently than traditional image-based methods. Available for Linux, macOS, and Windows operating systems.
dynobo10- LAREX

LAREX is a great open-source tool for analyzing the layout of early printed books. Its rule-based approach to connected components is not only efficient, but also easy to understand for the user. If needed, there is also an intuitive manual correction option.
In addition, the PAGE XML format makes it simple to integrate into existing OCR workflows. Evaluations have conclusively demonstrated that LAREX is an efficient and flexible solution for segmenting pages of early printed books, and is sure to meet all expectations.
LAREX can be installed thru Docker, or from source.
OCR4all11- OCRFeeder
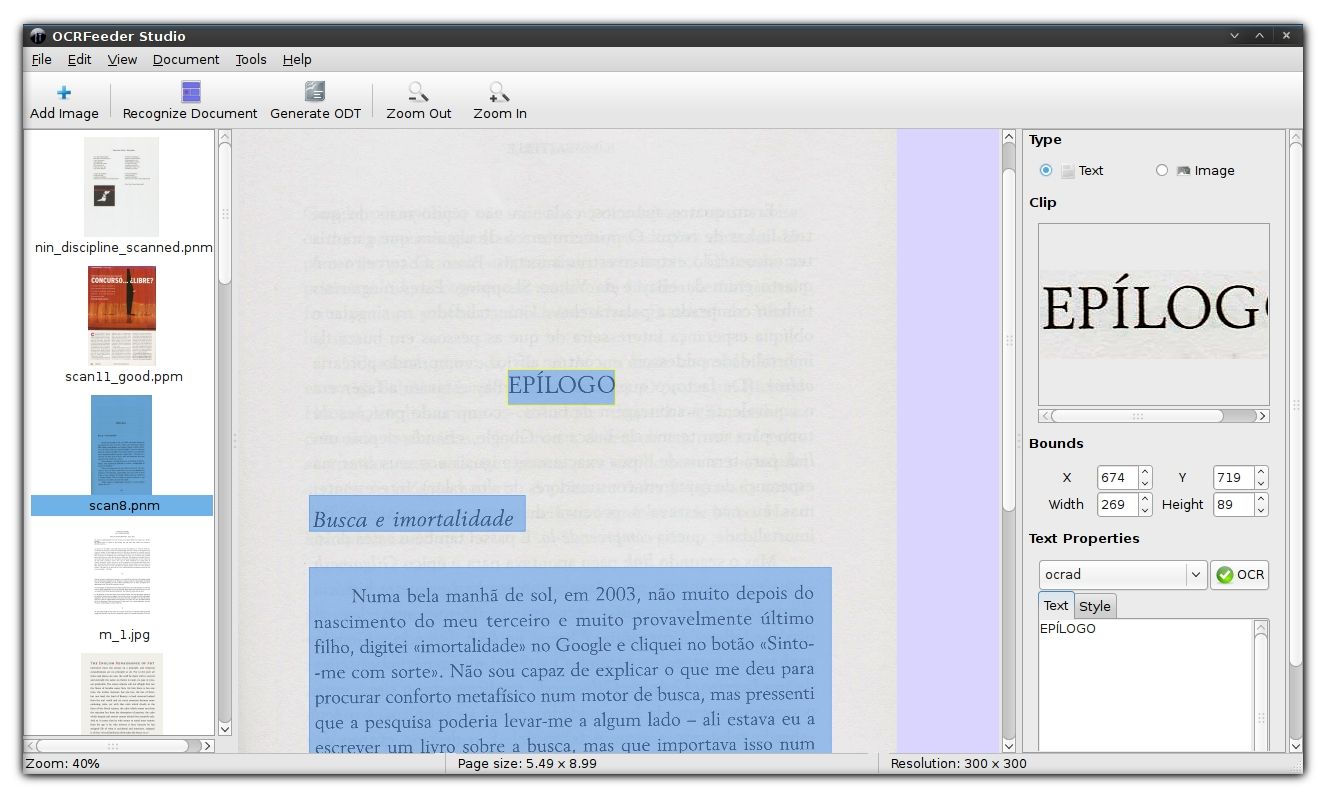
OCRFeeder is a powerful document layout analysis and optical character recognition system that automatically outlines content, distinguishes between graphics and text, and performs OCR over the latter. It generates multiple formats, with ODT as its main output.
With its complete GTK graphical user interface, users can confidently correct any unrecognized characters, define or correct bounding boxes, set paragraph styles, clean input images, import PDFs, save and load projects, and export everything to multiple formats.
OCRFeeder gives users the tools they need to efficiently and accurately process their documents.
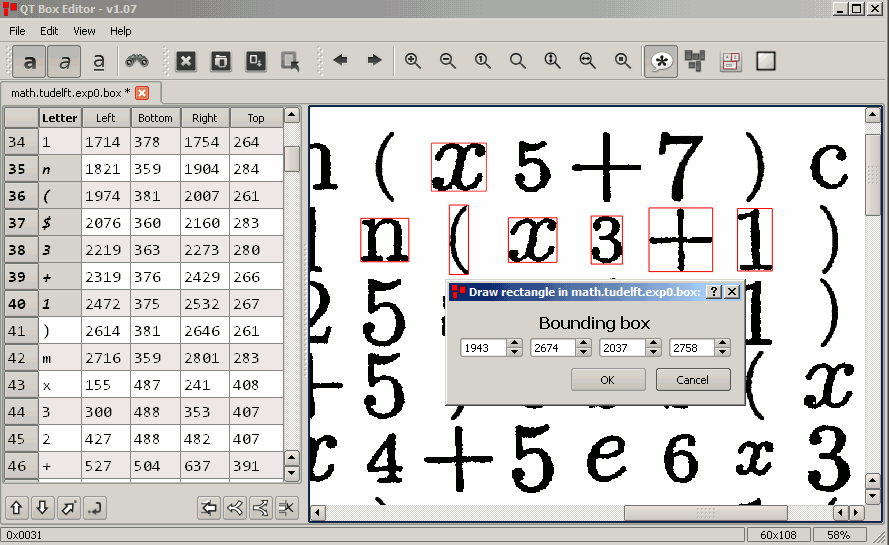
12- QT Box Editor
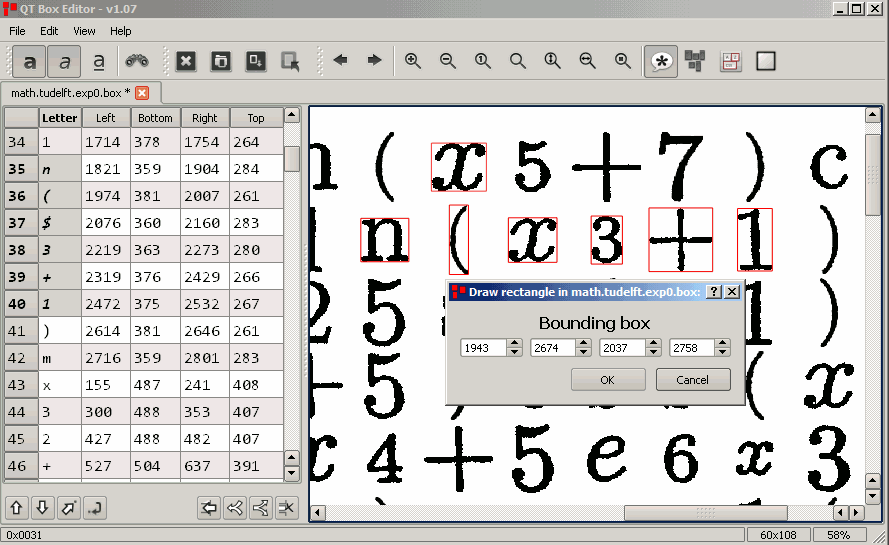
QT Box Editor is a tool used for adjusting box files in tesseract-ocr. The goal of this project is to provide an easy and efficient way to edit files, regardless of their size. QT box editor is the successor of the tesseract-gui project, which is no longer being developed.
 zdenop
zdenop13- Rescribe
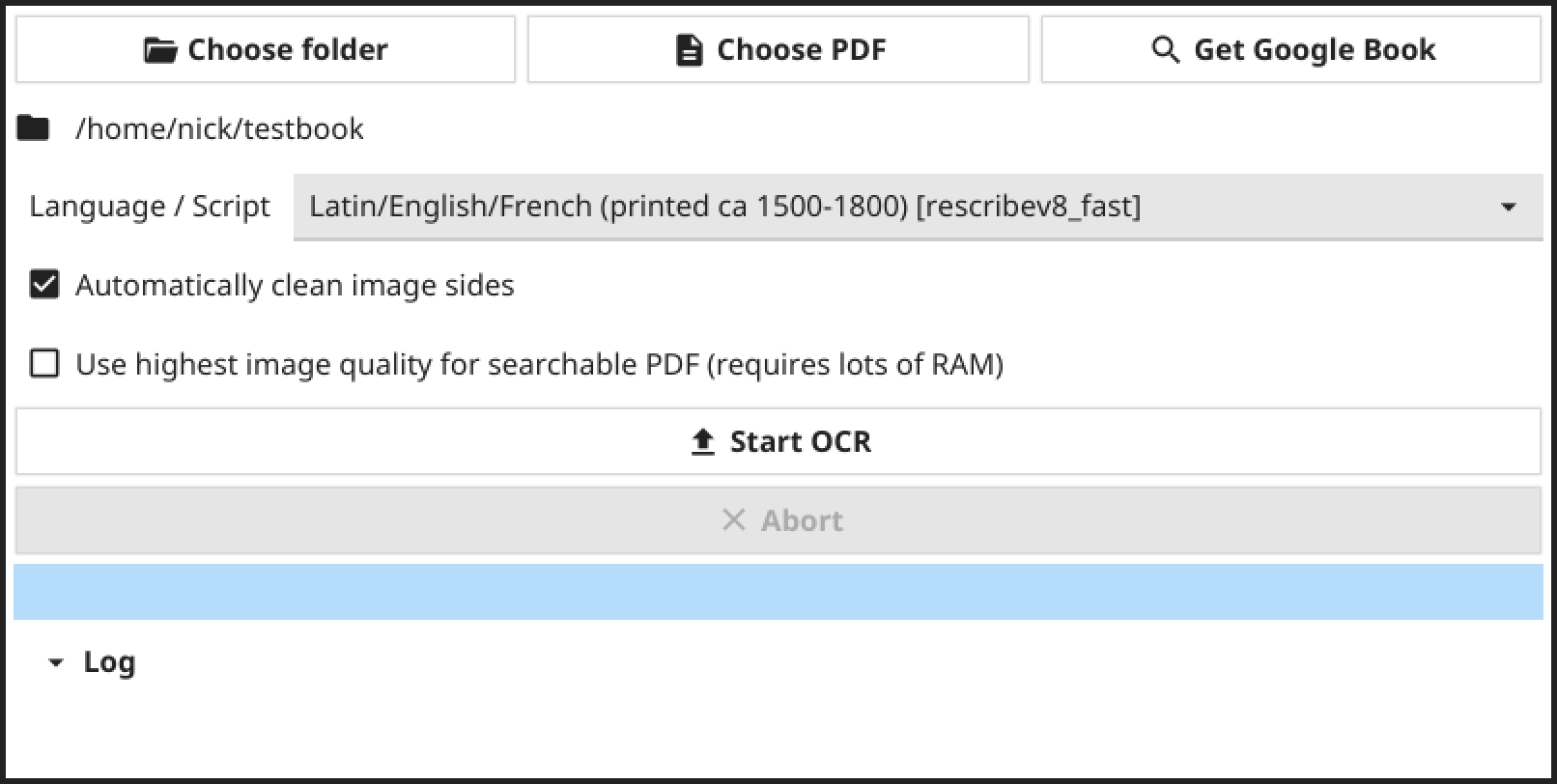
Rescribe is a desktop tool that allows you to easily perform OCR on image files, PDFs, and Google Books. It uses the Tesseract OCR engine along with efficient preprocessing and analysis pipelines to produce high-quality output. The tool is particularly useful for OCR of historical printed works, but it also includes modern language options and works well on modern printed works.
Rescribe is available for Windows, Linux, and macOS.
14- Cognitive OpenOCR
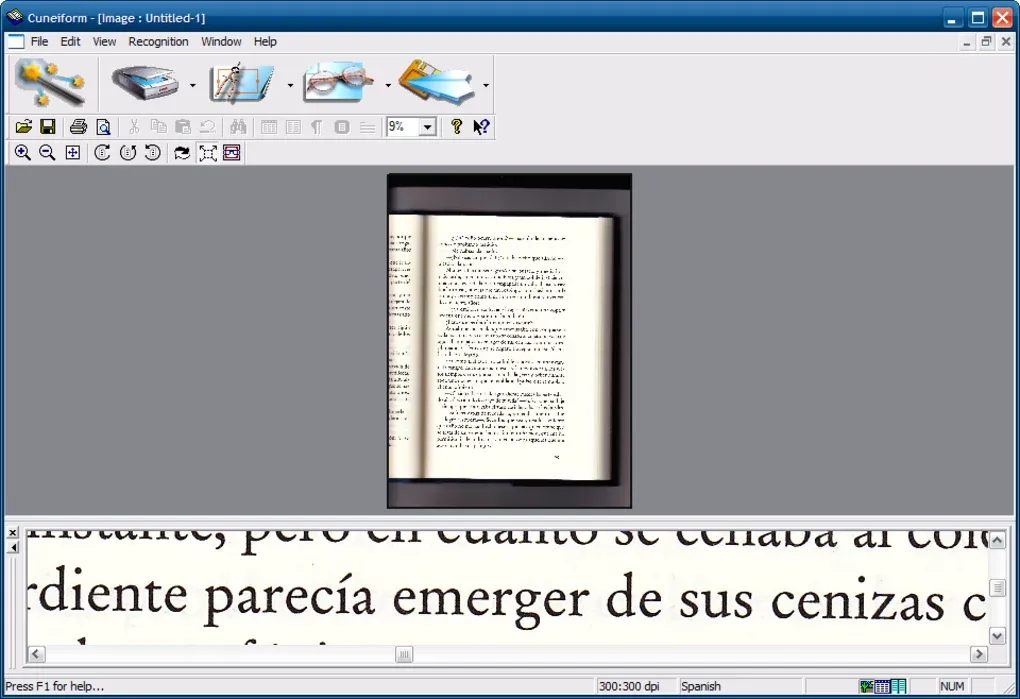
Cognitive OpenOCR is a free OCR program that combines databases from other openware OCR programs and user feedback. It offers 23 different language options and has avoidable bloatware options during installation.
15- OCRmyPDF
Hamza Mousa
16- Paperwork
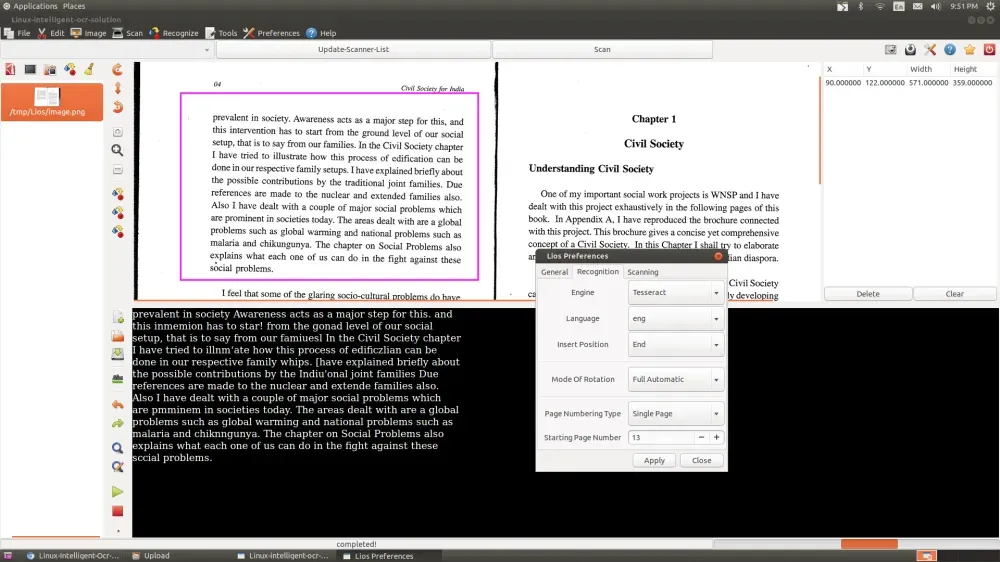
Hamza Mousa17- Lios OCR
 Hamza Mousa
Hamza Mousa18- NormCap
Hamza Mousa Hamza Mousa
Hamza Mousa Hamza Mousa
Hamza Mousa



