Table OCR - Free 11 OCR Apps to Extract Tables from Images and PDF Files


Table of Content
Table OCR: Extracting Data from Images and PDFs
OCR (Optical Character Recognition) is a technology designed to identify and extract text from images and scanned documents. While OCR tools are widely used to digitize printed text, handling complex layouts like tables presents unique challenges.
This article explores why extracting tables using OCR is not straightforward, introduces the concept of Layout OCR, and highlights the need for technical expertise to utilize some tools effectively.
Why Tables Are Difficult for OCR?
Extracting text from tables is fundamentally more complex than dealing with plain text. Here’s why:
- Complex Layouts: Tables often include rows, columns, merged cells, and nested tables, which OCR must interpret as structured data rather than plain text.
- Grid Recognition: Identifying grid lines and accurately associating text with specific cells is challenging, especially when tables lack clear borders.
- Alignment Issues: Scanned documents may have distortions, misaligned text, or inconsistent spacing, making it difficult for OCR to map the table correctly.
- Variability in Table Design: Tables come in diverse formats, such as financial reports, invoices, or scientific tables, each requiring tailored recognition strategies.
 Hazem Abbas
Hazem Abbas
Layout OCR: A Specialized Approach
To tackle these challenges, Layout OCR focuses on detecting and interpreting document layouts, including tables, charts, and diagrams. Unlike traditional OCR, Layout OCR integrates advanced techniques such as:
- Structure Detection: Identifying sections of a document, including headers, footers, and tabular regions.
- Grid Extraction: Parsing tables and maintaining their original structure.
- AI Integration: Leveraging machine learning to improve recognition accuracy for complex layouts.
Layout OCR is a game-changer, but its implementation often requires sophisticated tools and expertise, making it less accessible for casual users.
Best Free and Open-Source Table OCR Tools
We’ve compiled a list of 11 free and open-source tools designed for extracting tables from images and PDFs. These tools include both general-purpose OCR systems and specialized solutions for handling tables. However, many of these require technical knowledge and scripting skills for effective use.
From installation to running custom scripts for table extraction, users may need a strong understanding of programming or command-line interfaces.
While we will provide the full list later, it’s worth noting that these tools are a great starting point for developers, researchers, and professionals who need precise table extraction without relying on proprietary software.
1- Hyper-Table-OCR
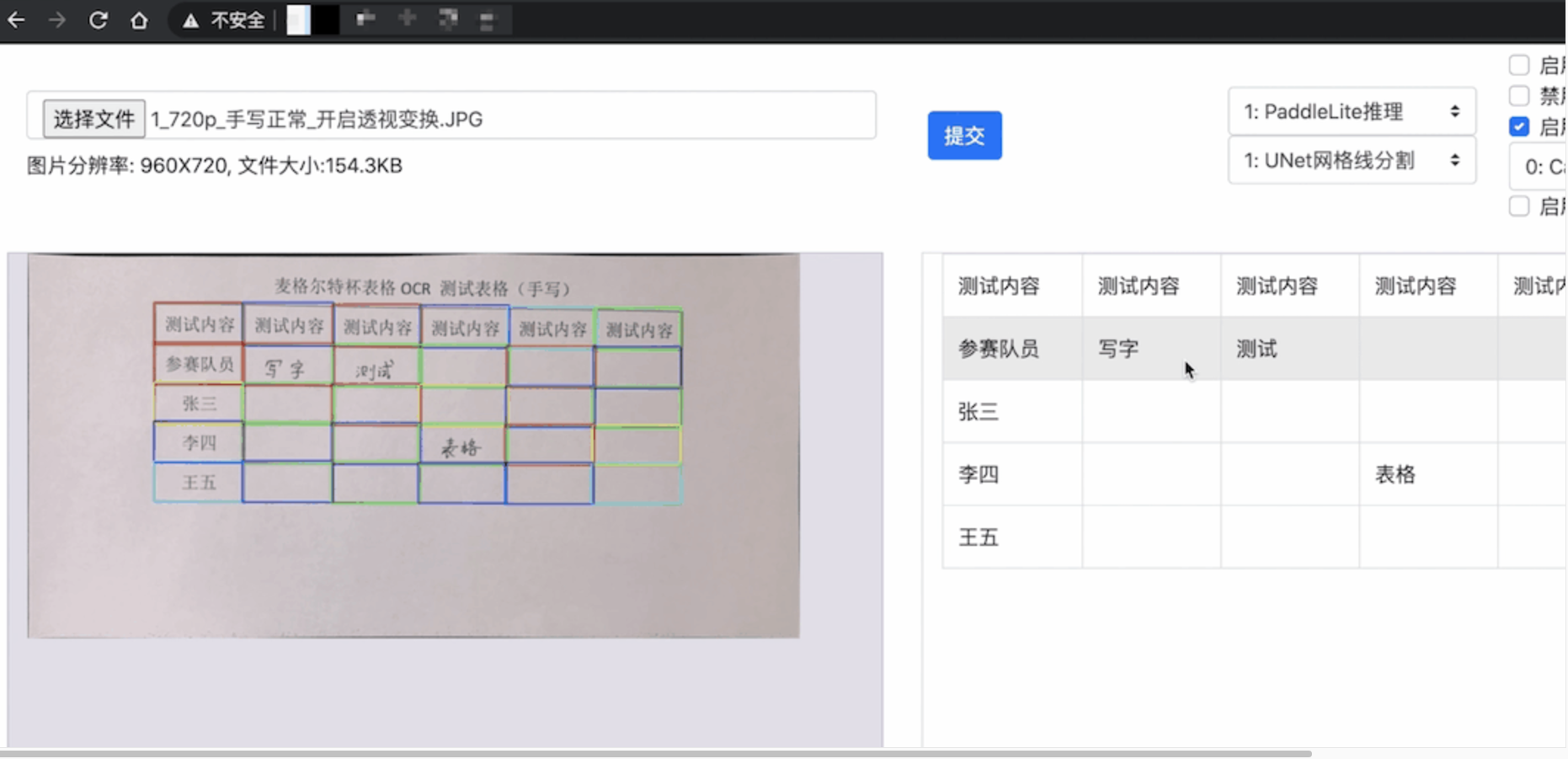
A carefully-designed OCR pipeline for universal boarded table recognition and reconstruction.
This pipeline covers image preprocessing, table detection(optional), text OCR, table cell extraction, table reconstruction.
Features
- Flexible modular architecture: by deriving from predefined abstract class, any module of this pipeline can be easily swapped to your preferred one.
- A simple yet highly legible web interface.
- A table reconstruction strategy based simply on coordinates of each cell, including identifying merged cell row & building table structure.
2- Table-Extraction-using-OCR
This is a Python implementation for converting tables in PDF documents to Excel format using Optical Character Recognition (OCR) and OpenCV. The input PDF document can be found in input/test_input.pdf. The screenshot of the PDF document used is shown below
The table is extracted and converted to an eExcel file in output/pdf2excel.xlsx.
 ajay960singh
ajay960singh3- TableCV
TableCV is a Python package designed to extract tables from images. It offers two approaches for extracting tables, allowing you to choose the one that best suits your needs.
inquilabee4- img2table
img2table is a simple, easy to use, table identification and extraction Python Library based on OpenCV image processing that supports most common image file formats as well as PDF files.
5- Surya
Surya is a powerful open-source OCR toolkit designed to handle a wide range of document processing tasks with impressive precision and flexibility.
It excels in various aspects of OCR and layout analysis, making it a standout option for users seeking an open-source alternative to proprietary cloud-based services.
While Surya offers exceptional functionality, it does require technical knowledge and scripting expertise to set up and use effectively. Users comfortable with programming or automation can leverage Surya for tasks like large-scale document processing or data extraction from structured layouts.
Features
- Multilingual OCR:
Surya supports OCR in over 90 languages, benchmarking favorably against leading cloud services. Its multilingual capability makes it ideal for global users working with diverse document sets. - Line-Level Text Detection:
The toolkit accurately detects and extracts text at the line level in any language, ensuring high fidelity in text representation. - Advanced Layout Analysis:
Surya goes beyond basic OCR with layout analysis, identifying elements such as:- Tables
- Images
- Headers
- Footers
This enables precise reconstruction of complex document structures.
- Reading Order Detection:
For documents with non-linear reading patterns, Surya automatically determines the reading order, maintaining the logical flow of extracted text. - Table Recognition:
A standout feature, Surya detects rows and columns within tables, making it highly effective for tabular data extraction—a feature that many general-purpose OCR tools struggle with.
VikParuchuri6- OCR Table
Surya is an advanced OCR toolkit supporting over 90 languages with exceptional table recognition capabilities. Unlike traditional OCR tools, it retains table structures and exports results into editable formats like Microsoft Word.
It is designed with both developers and professionals in mind, Surya offers robust features for handling complex documents effectively.
Features
- Multilingual OCR
Supports over 90 languages, including Chinese character recognition, leveraging Tesseract's pre-trained models. - Table Structure Recognition
Accurately detects rows and columns in tables, preserving the structure during text extraction. - Layout Analysis
Identifies headers, footers, and images in scanned copies. - Reading Order Detection
Maintains logical text flow in documents with complex layouts. - Cross-Platform Components
Includes 64-bit DLL for core functions (C++) and an EXE user interface (C#).
bitdata7- ocr-table
OCR-Table is a project designed to extract table structures from scanned image PDFs using Optical Character Recognition (OCR). It preserves the layout, including rows and columns, ensuring tables are accurately recognized and saved in editable formats like Microsoft Word.
This tool is ideal for users needing structured data from complex documents.
cseas8- TabularOCR
TableOCR is a powerful and versatile Python library that provides an easy-to-use Optical Character Recognition (OCR) solution for extracting tables from images and PDFs.
The app offers flexible output options, allowing you to export the extracted data in CSV, XLSX, or other spreadsheet formats.
Features
- Accurate Table Detection: TableOCR uses advanced computer vision algorithms to accurately detect and extract tables from images and PDFs, even in challenging scenarios with complex layouts or low-quality scans. It employs techniques such as edge detection, connected component analysis, and deep learning-based object detection to locate and isolate tables within the input document.
- Multiple Input Formats: Supports a wide range of input formats, including PNG, JPG, BMP, TIFF, and PDF files, allowing for flexibility in processing various types of document sources.
- Customizable Output: Offers flexible output options, allowing you to export the extracted data in CSV, XLSX, or other spreadsheet formats of your choice, ensuring seamless integration with your existing data processing workflows.
- Batch Processing: Easily process multiple files in a directory or a folder structure, making it ideal for high-volume data extraction tasks, such as digitizing large archives or processing scanned documents at scale.
- Multi-language Support: Leverages state-of-the-art OCR engines to support a wide range of languages, enabling accurate table extraction from documents in various languages, including English, Spanish, French, German, Chinese, Arabic, and many more.
- Parallel Processing: Utilizes multi-threading and parallel processing capabilities to speed up the table extraction process, significantly reducing processing times for large datasets or complex documents.
- Configurable Settings: Provides a range of configuration options to fine-tune the table extraction process, including options for adjusting image pre-processing (e.g., deskewing, denoising, and binarization), OCR engine settings (e.g., language packs, character whitelists), and output formatting (e.g., column delimiters, date formats).
- Embedded OCR Engines: TableOCR comes bundled with several popular OCR engines, including Tesseract and LSTM-based models, ensuring high accuracy and flexibility in table extraction. Additional OCR engines can be easily integrated, thanks to the modular design of the library.
- Seamless Integration: Designed with a user-friendly API, TableOCR can be easily integrated into your existing Python projects, allowing for efficient table data extraction and analysis workflows, enabling applications in areas such as data mining, research, and business intelligence.


9- Camelot: PDF Table Extraction for Humans
Camelot is a Python library for extracting tables from text-based PDF files. It offers high accuracy, export options, and seamless integration with data analysis workflows, making table extraction efficient and customizable.
Features
- Extracts tables from text-based PDFs.
- Exports to multiple formats: CSV, JSON, Excel, HTML, and SQLite.
- High accuracy with parsing reports and discardable bad tables.
- Outputs tables as pandas DataFrames for ETL and analysis.
- Command-line interface for quick usage.
- Fully customizable for tweaking extraction settings.
atlanhq10- GMFT
GMFT is a lightweight and fast toolkit designed for extracting tables from PDF files and converting them into various formats. Built on Microsoft’s Table Transformers, it offers exceptional performance, reliability, and flexibility for users who need high-quality table extraction without the overhead of heavy dependencies or GPU requirements.
Features
- High-quality table extraction using Microsoft’s Table Transformer.
- Exports to multiple formats: DataFrames, CSV, JSON, Markdown, and cropped images.
- Fast and lightweight; no GPU required, minimal dependencies.
- Reliable performance on complex table structures (e.g., scientific papers).
- Easy installation via
pipwith minimal setup. - Configurable and modular for custom workflows.
conjuncts11- Table Transformer (TATR)
Table Transformer (TATR) is a deep learning model for extracting tables from unstructured documents (PDFs and images). This is also the official repository for the PubTables-1M dataset and GriTS evaluation metric.
microsoftConclusion
Extracting tables with OCR is no simple task due to the intricate structure of tabular data. Layout OCR offers a specialized solution, but technical barriers still exist.
Whether you’re working on digitizing financial records or analyzing scanned reports, open-source table OCR tools can be powerful allies if you’re ready to invest time in understanding and configuring them. Stay tuned for our detailed list of the best free and open-source tools to help you get started.
Looking for More OCR Resources?
- OCRmyPDF: OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched (Free software)
- Tabula OCR - Free Tool to Extract Tables from PDF Files for Windows and macOS
- LaTeX-OCR: Free and Open-Source Python-based OCR for Scientific Document Conversion
- Scribe OCR - Free Web OCR That you can Self-host
- 12 Free OCR Libraries and Projects
- Web-based OCR app for Firefox and the Web
- Capture2Text: The Ultimate OCR Tool for Effortless Text Extraction and Translation
- Best 9 Commercial PDF Editors with OCR support for Windows Power Users, Choose the Best one
- 13 Best Open Source Free PDF OCR Text Extractors