How and Why TOON will Save Your AI App from a Massive Bill?
The TOON Revolution: How a Simple Format Can Slash Your Future AI Bill

From Prototype to Production: Our AI Journey at TakeAsIstan
Here at TakeAsIstan, our AI-powered classifieds platform currently in development, we're building in the trenches. We're not just sketching wireframes; we're stress-testing with thousands of simulated listings and real-world data dumps.
Parallel to this, our team is incubating several healthcare applications designed to process sensitive patient summaries. Like most developers, we defaulted to JSON. It was the reliable backbone of our prototypes, perfect for our internal APIs.
But as our simulated user loads scaled from hundreds to millions of AI interactions during testing, a stark forecast appeared in our projections: an unsustainable curve of token-driven costs.
What Exactly Is a "Token," and Why Does It Matter?
Let's clear up the jargon. In AI, a "token" isn't a digital coin; it's the fundamental unit of consumption for models like GPT-4 or Claude. When you send a prompt, your text is chopped into these tokens, common words might be one, complex words or even parts of words can be several.
For AI services, tokens are the meter running. You pay per thousand tokens for what you send and for what you get back. It's like being billed by the syllable for a crucial business conversation. Every character counts.

The Hidden Cost of Our Default Workflow
Our initial approach was standard: we built rich, nested JSON objects for our AI agents. A test listing in TakeAsIstan wasn't just basic info. It was a structured document with location objects, arrays of image metadata, and user interaction histories, great for developers, brutally verbose for the AI. Every curly brace {, every quotation mark ", every colon and comma was a billable token.
We realized the structural scaffolding, the syntactic glue, was costing us almost as much as the actual data. In some test batches, over 40% of the tokens were just punctuation. We were projecting massive bills for sending syntactic repetition.
The core issue isn't that JSON is bad, it's that it's built for machine parsing, not for token-efficient AI communication. LLMs are brilliant pattern recognizers. They don't need the rigid, repeated syntax to understand a list; they can infer structure from cleaner, more human-like patterns.
Discovering TOON: Our Efficiency Upgrade Mid-Development

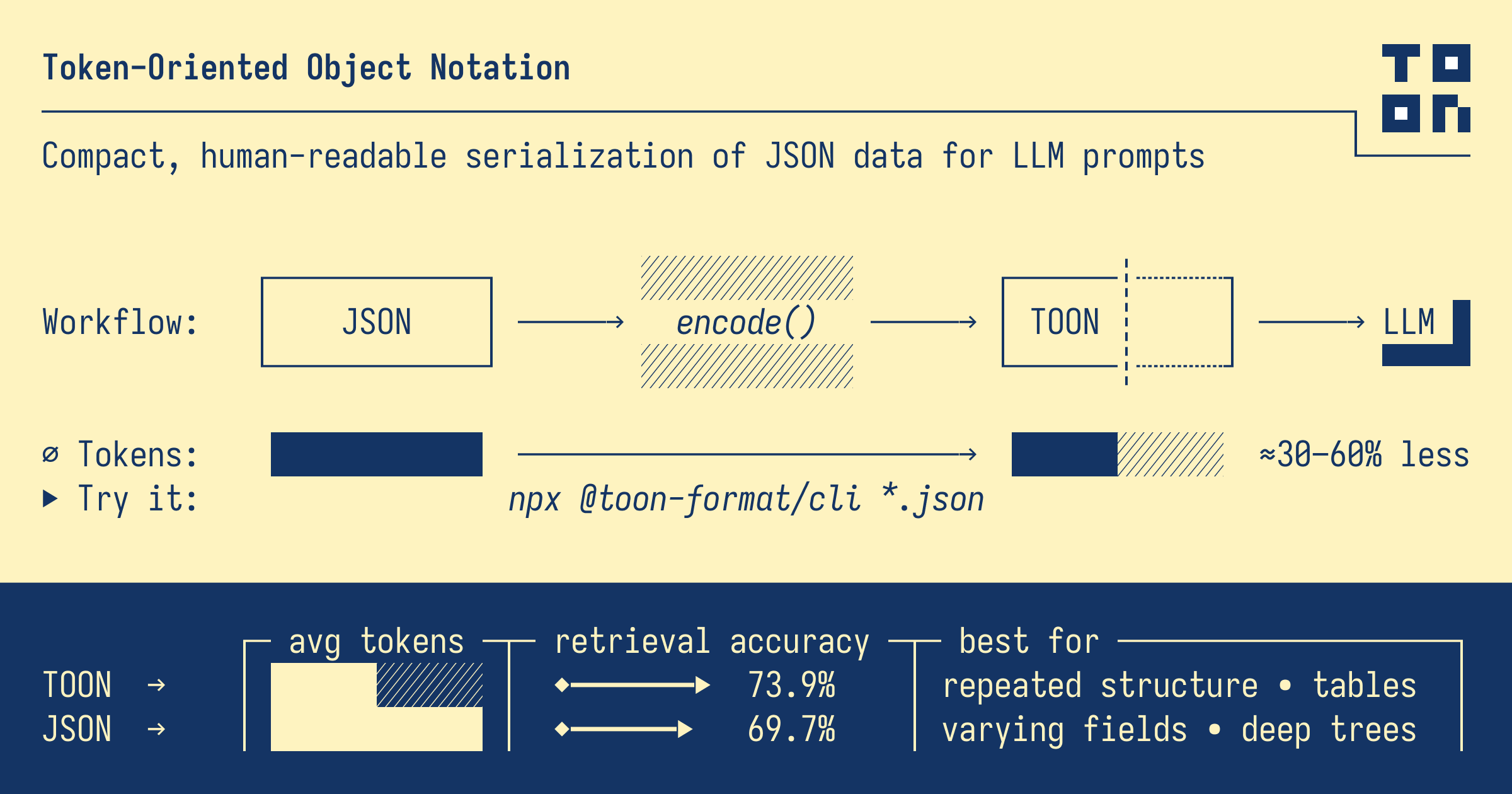
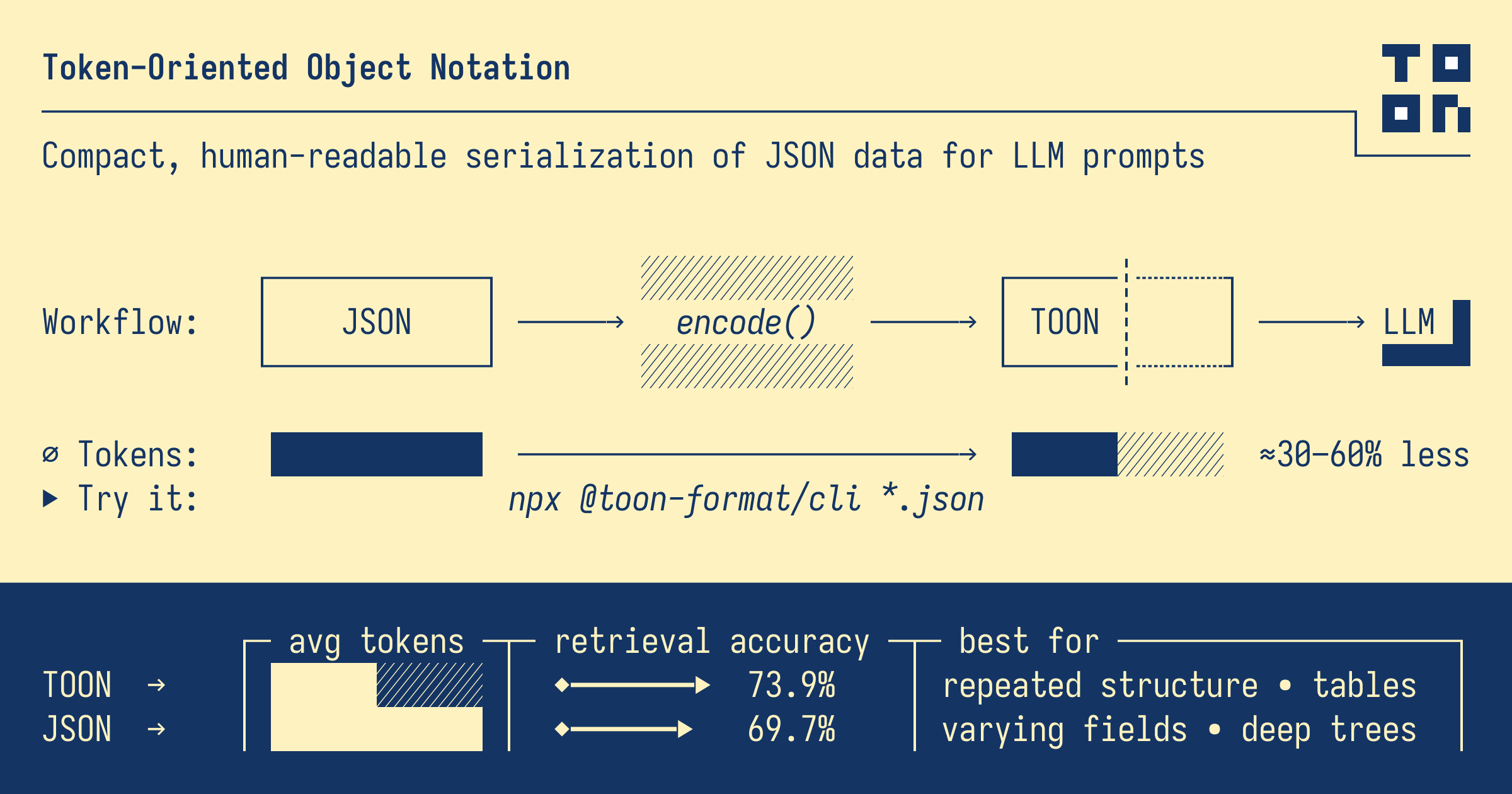
This looming cost crisis led us to Token-Oriented Object Notation (TOON). We're now actively integrating it into our development pipeline. TOON is a pragmatic reimagining of data for AI. It answers a critical question: What is the minimal, clearest signal an LLM needs to reconstruct perfect JSON?
TOON cleverly merges two intuitive formats: YAML's indentation for nesting objects and CSV's tabular style for uniform arrays, the workhorse of most data feeds.
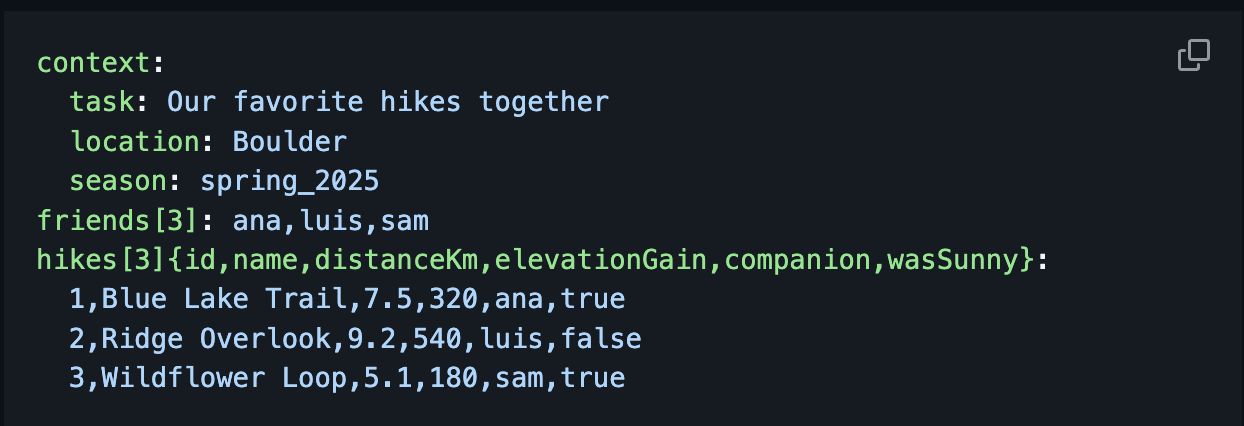
Here’s a snapshot from our TakeAsIstan test environment. A simulated batch of apartment listings transforms:
The Old JSON Prototype: A repetitive blast of [{, "key":, and }, { for every item.
The New TOON Test Feed:
listings[3]{id,title,price_eur,location,bedrooms}:
101,Modern Loft Downtown,1200,Center,1
102,Suburban Family Home,2000,East,3
103,Riverside Studio,950,Riverside,1
The efficiency is in the header line: listings[3]{id,title...}:. It instantly tells the AI: "Here's an array called 'listings' with 3 items, each having these five fields in order."
The data follows in a clean, comma-separated table. The LLM understands it flawlessly. The structure is explicit yet stunningly compact.
The Tangible Impact: Guarding Our Runway
While TakeAsIstan is still in development, the math from our simulations is compelling. In tests with our healthcare app prototypes, sending batches of anonymized patient metrics as TOON reduced prompt sizes by an average of 40-45%.
For a launch-scale system, this isn't a minor optimization, it projects to a near-halving of a major future cost line: model inference.
This efficiency gain means we can now design to send richer context, more detailed listings, or longer patient histories within the same computational budget, making our AI features more powerful without breaking the bank.
A Strategic Tool, Not Yet a Total Replacement
It's important to note: TOON isn't a silver bullet for all data. Deeply nested, irregular structures might still be clearer in JSON. But for the common AI prompting patterns, sending lists of records, configuration objects, or uniform logs, TOON is a revelation.
For us, it acts as a strategic translation layer: use JSON in our application logic, encode it as hyper-efficient TOON for the AI, and decode any TOON response back.
TOON Key Features
Token-Frugal & Hyper-Accurate: Outperforms JSON in data fidelity, achieving 74% task accuracy across models while consuming ~40% fewer tokens. It’s not just smaller; it’s smarter.
Lossless JSON Mirror: Every valid JSON structure has a deterministic TOON representation. Convert back and forth without losing a comma, it’s the same data model, just wearing different clothes.
Built-in Schema Guardrails: Every tabular array declares its size [N] and fields {...} upfront, giving LLMs a clear blueprint to follow. This reduces parsing errors and hallucinated structures.
Punctuation on a Diet: Replaces bulky braces and excessive quoting with clean indentation and strategic commas. YAML’s readability meets CSV’s raw compactness.
Tabular Superpowers: Uniform arrays of objects collapse into sleek, header-defined tables. Declare fields once, stream rows line by line, like CSV, but with explicit, enforceable structure.
Polyglot from Day One: A strict, open specification drives native implementations in TypeScript, Python, Go, Rust, .NET, and more. Works in your stack, not against it.
Drop-In, Not Rework: Designed as a pre-processor step. Keep using JSON in your app logic, encode to TOON just before the LLM call, decode back after. Zero architectural overhaul required.
Model-Tested, Not Just Theorized: Benchmarked across GPT, Claude, Gemini, and Llama families. The syntax is shaped by what actually improves model comprehension and output reliability.
File-Friendly Convention: Use the .toon extension and text/toon media type for clear intent. UTF-8 native, simple to stream, easy to store.
Where TOON Falls Short
TOON excels with uniform object arrays, but certain cases favor other formats:
- Deeply nested, non‑uniform data (e.g., complex config objects) → JSON is more compact.
- Semi‑uniform arrays (∼40‑60% tabular eligibility) → token savings diminish; stick with JSON if pipelines already use it.
- Pure flat tables → CSV is smaller. TOON adds minor overhead (∼5‑10%) for structural guardrails.
- Latency‑critical workloads → benchmark both. Some deployments (like local/quantized models) may process compact JSON faster despite TOON’s lower token count. Measure TTFT, tokens/sec, and total time.
In short: TOON is a specialist for uniform tabular data. For highly nested, semi‑uniform, or pure‑tabular cases, JSON or CSV often win. Always test in your specific environment.
TOON Benchmarks: More Accurate, Fewer Tokens
The Testing Philosophy
To provide fair and meaningful comparisons, benchmarks are organized into two distinct tracks:
- Mixed-Structure Track: Tests datasets with nested or semi-uniform data (TOON vs. JSON, YAML, XML). CSV is excluded here because it cannot properly represent these complex structures.
- Flat-Only Track: Tests purely tabular, flat datasets where CSV is applicable (CSV vs. TOON vs. JSON, YAML, XML).
The primary goal is to measure LLM comprehension and retrieval accuracy, not the model's ability to generate TOON, but its ability to read and understand data presented in each format.
The Efficiency Champion
When measuring accuracy per 1,000 tokens, the most telling metric for cost-conscious AI development, TOON emerges as the clear leader:
TOON: 26.9 accuracy%/1K tokens (73.9% accuracy with 2,744 tokens)
JSON Compact: 22.9 accuracy%/1K tokens (70.7% accuracy with 3,081 tokens)
YAML: 18.6 accuracy%/1K tokens (69.0% accuracy with 3,719 tokens)
Standard JSON: 15.3 accuracy%/1K tokens (69.7% accuracy with 4,545 tokens)
XML: 13.0 accuracy%/1K tokens (67.1% accuracy with 5,167 tokens)
The bottom line: TOON achieves 73.9% accuracy versus JSON's 69.7% while using 39.6% fewer tokens. This isn't just smaller data, it's more accurate data delivery.
Real-World Testing Scenarios
The benchmark utilizes eleven datasets covering practical structural patterns:
- Tabular Data: 100 uniform employee records (TOON's sweet spot)
- Complex Structures: 50 nested e-commerce orders with customer objects and item arrays
- Time-Series: 60 days of analytics metrics
- Real-World Data: 100 GitHub repositories from top projects
- Semi-Structured: 75 event logs with mixed flat and nested error objects
- Deep Configuration: Complex, deeply nested config objects
Additionally, five structural validation datasets test how well each format helps LLMs detect corrupted or incomplete data, a key advantage of TOON's explicit metadata.
The Bottom Line for Builders

In the new economy of AI, where every token carries a cost, efficiency is critical for sustainability. TOON is the practical upgrade we're implementing now, before scaling. It turns costly data packaging into a streamlined data stream.
For any development team, especially in the startup or growth phase, adopting TOON isn't just a technical tweak, it's a vital financial safeguard.
At TakeAsIstan, integrating TOON is a core architectural decision, one that proactively protects our runway from the silent, creeping tax of wasteful tokens. It’s the kind of smart foundation you build before the bills start arriving.
Resources