17 Free Solutions to Open and Manage Large Text, CSV and Excel Files

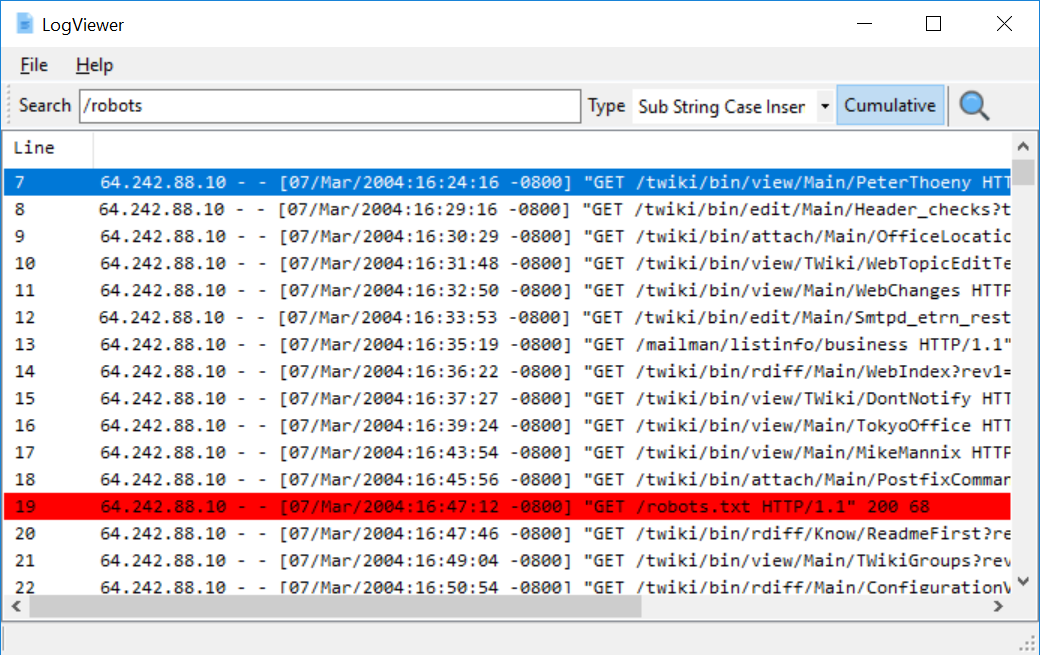
Table of Content
Reading large text files is essential for various use cases in data processing and analysis. Here are some reasons why reading large text files is needed:
1. Big Data Analysis: With the increasing volume of data being generated, organizations often need to analyze large text files to extract valuable insights. This includes processing log files, analyzing customer feedback, or performing sentiment analysis on social media data.
2. Data Cleaning and Preprocessing: Large text files may contain noisy or unstructured data that requires cleaning and preprocessing. By reading these files, data scientists can perform tasks like removing duplicates, normalizing text, or extracting relevant information.
3. Machine Learning and Natural Language Processing: Large text files are commonly used in machine learning and natural language processing tasks. Training models for sentiment analysis, text classification, or language translation often require reading and processing large text datasets.
4. Log Analysis: In fields like cybersecurity and system monitoring, log files can contain crucial information about events and errors. Efficiently reading and analyzing large log files can help identify anomalies, troubleshoot issues, and improve system performance.
5. Text Mining and Information Retrieval: Large text files are a valuable source of information for text mining and information retrieval tasks. These tasks involve extracting meaningful patterns, keywords, or entities from text, enabling advanced search capabilities or building recommendation systems.
To handle large text files efficiently, various tools and techniques are available. These include libraries like LLPAD, FileReader, TextReader, and TxtReader, which allow for streaming and processing files in smaller chunks to prevent memory overload. Specialized text editors like WindEdit and LogViewer are designed to handle large files and provide features like search, filtering, and navigation.
In programming languages like Python, libraries such as pandas and Dask offer efficient ways to read and process large text files. They provide mechanisms like chunking and parallel processing to handle large datasets while minimizing memory usage.
For distributed computing and big data processing, frameworks like Apache Spark are widely used. Spark enables reading and processing large text files by distributing the workload across a cluster of machines, ensuring scalability and fault tolerance.
Reading large files!
Handling large text, CSV, and Excel files is a common challenge in data processing and analysis. When working with massive datasets, traditional software and tools may struggle to efficiently read, process, and analyze such files.
Fortunately, there are several free and open-source solutions available that can help overcome these limitations and empower users to work with large files effectively.
1- GNU Core utilities
GNU Core Utilities is a collection of essential command-line tools for Unix-like operating systems. These utilities provide basic functionality for file manipulation, text processing, shell scripting, and more. Some of the commonly used tools included in GNU Core Utilities are ls (list files), cp (copy files), mv (move files), rm (remove files), cat (concatenate and display files), grep (search for patterns in files), and sed (stream editor for text transformation).
These utilities are widely used and provide a foundation for various tasks in Unix-like systems.
- Split: Divides large files into smaller, more manageable pieces with confidence.
- Grep: Confidently searches through large files for specific patterns.
- Awk: Confidently processes and analyzes text files.
- Sed: Confidently filters and transforms text using a stream editor.
These tools are confidently standard on Unix-like systems and can be confidently combined to efficiently process large text files.

2- Python
1- Basic Python
 Hazem
Hazem Hazem
Hazem
2- Using Pandas
While pandas itself might struggle with loading a 20GB file into memory all at once, it can be used to process chunks of the file incrementally. This incremental processing capability of pandas allows for efficient handling of large datasets, as it avoids overwhelming the memory.
By breaking down the file into smaller manageable chunks, pandas can perform computations and analysis on each chunk individually, and then combine the results to obtain the desired output.
3- Dask
Dask is a parallel computing library that scales to larger-than-memory computations. Dask can work with large datasets by breaking them into smaller chunks and processing these chunks in parallel.
In this following tutorial, we will guide you on how to use Dask to read large files.
Hazem
3- LLPAD
This is a free and open-source Java app that enables you to read large text files up to 100GB.
It can be installed on Windows, Linux, and macOS.
How does it work?
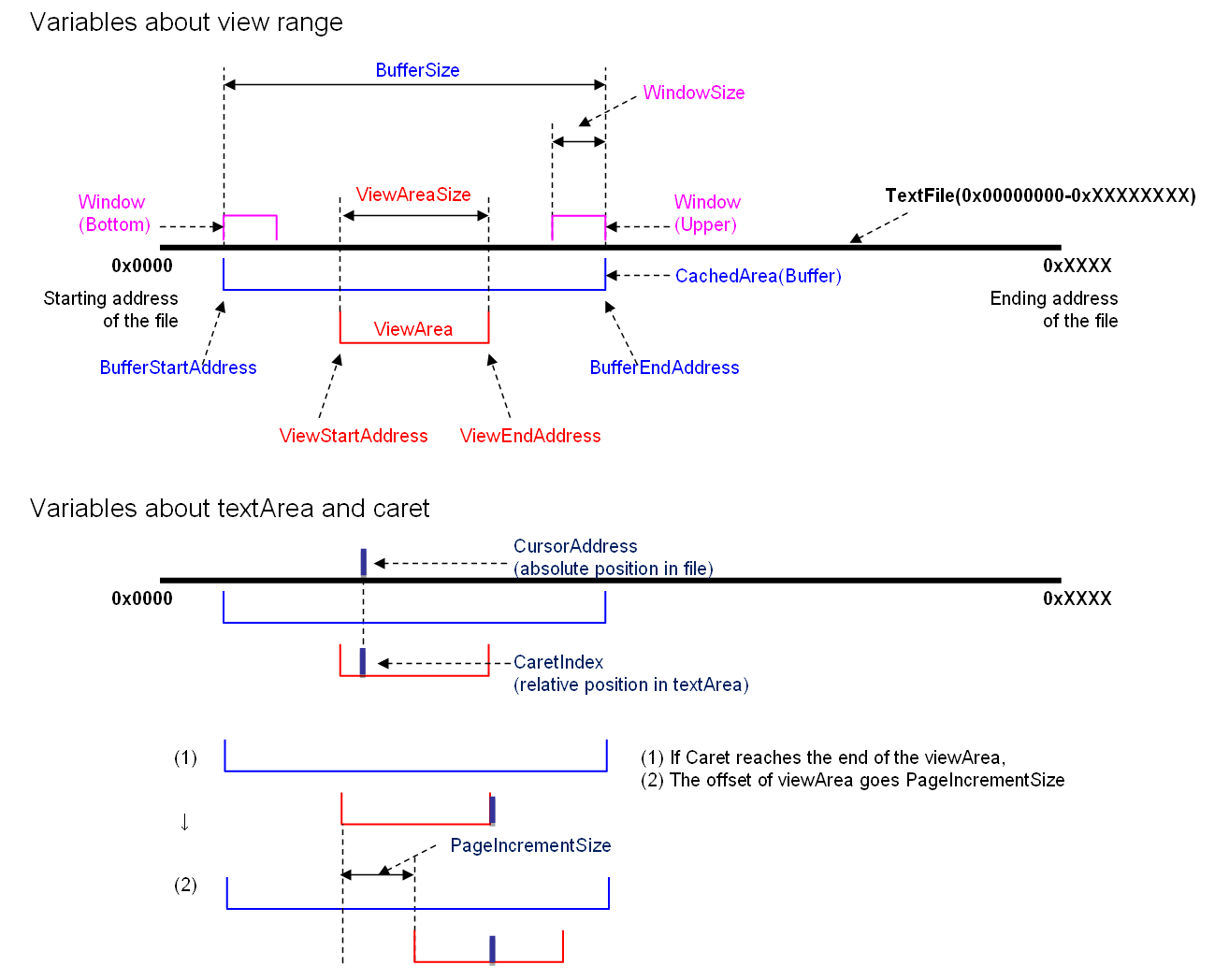
- LLPAD does not read the entire file at once.
- To handle large files, LLPAD reads only a small part of the file into a buffer (CachedArea).
- The portion of the buffer that is displayed in the text area is referred to as the viewArea.
- As the caret is moved, the viewArea also moves. When the viewArea reaches the end of the buffer, the next portion is read into the buffer.
 riversun
riversun4- FileReader
FileReader is a C# library by Agenty that allows for reading and processing large text files with pagination to prevent out of memory exceptions. It streams the file instead of loading the entire content into memory, making it suitable for files around 500 MB or larger.
Agenty5- TextReader
TextReader is an Electron-based utility for reading large text files in small pieces (1000 bytes each) to avoid loading them into memory.
limitedeternity6- WindEdit
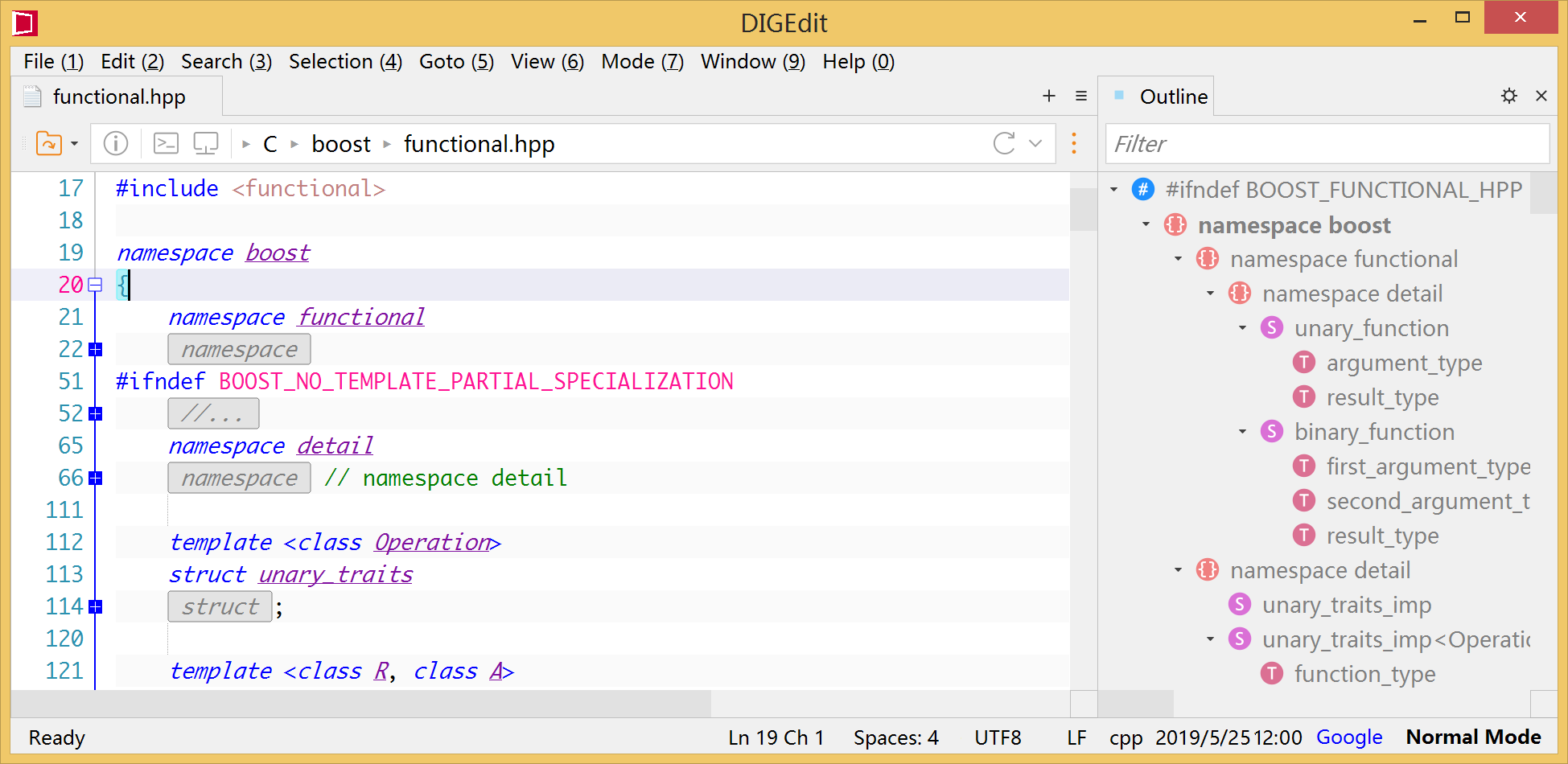
WindEdit is a free text editor designed for handling large files and long lines. It is high-performance and can be used for both commercial and non-commercial purposes. The source code is shared with WindTerm, which can be found on the WindTerm GitHub page.
Features
- Support huge files upto TBytes.
- Support huge files containing billions of lines of text.
- Support very long lines upto GBytes.
- Support vscode syntaxes. (Currently only support cpp, python, rfc, and more is coming)
- Support vscode themes.
- Configurable fold, pair, indent, outline, complete, mark and so on.
- Snippet.
- Word wrap.
- Hex edit.
- Column edit.
- Multilines edit.
- Search and replace in folders.
- High performance.
kingToolboxHazem
7- TxtReader
TxtReader is a JavaScript library that uses the FileReader API and Web Worker to read very large files in browsers without blocking UI rendering. It provides promise-like methods to track the reading progress.
js10168- LogViewer
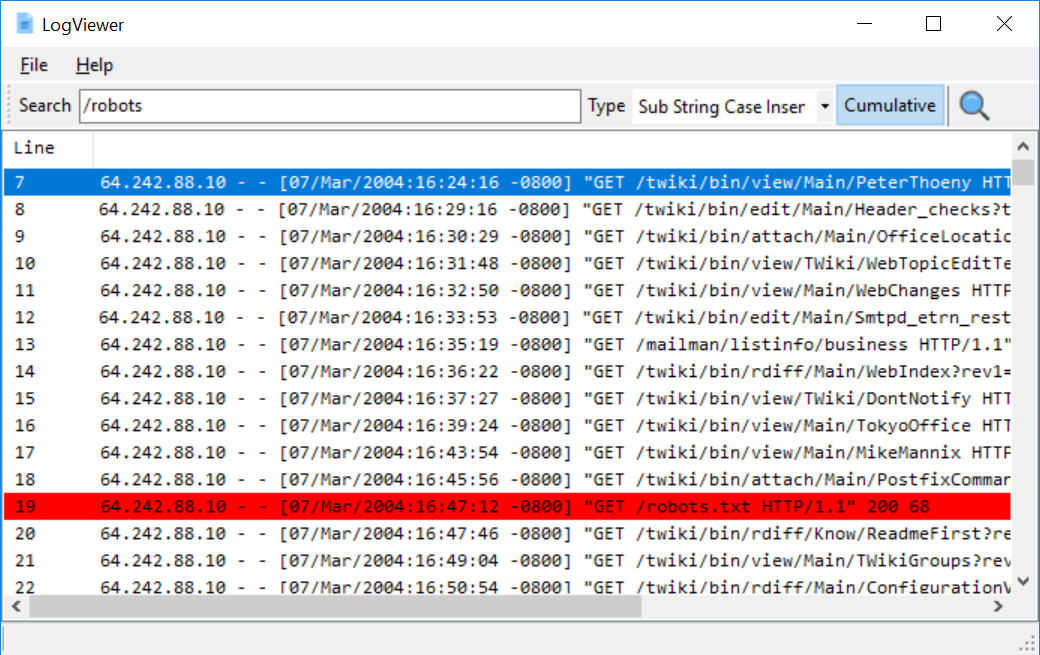
LogViewer is a tool for opening, viewing, and searching large text files, specifically for log analysis in DFIR cases. It allows users to search for terms, hide lines, and provides an overview of the log file contents and actions performed. Some features include stopping actions by double-clicking the progress bar and accessing actions through the context menu.
Features
- Very fast
- Supports huge files
- Cumulative search
- Can disable/enable search terms that are cumulative and the results are displayed instantly
- Export current view
- Show/Hide matched lines
- Four search modes (Sub String Case Insensitive, Sub String Case Sensitive, Regex Case Insensitive, Regex Case Sensitive)
woanware9- BigFiles (Notepad++)
BigFiles is a free and open-source Notepad++ to read large text files.
superolmo10- Large Text File Reader
This program allows reading large text files without opening them completely, by reading a given number of lines at a time. It is easy to use and allows copying the viewed text.
Features
- Reading Large Text Files
- Reading a given Number of lines at a time,not the whole file
- Easy to use
- Copy the text viewed
11- HugeFiles
Yet another Notepad++ plugin for viewing and editing very large files.
Features
- You can choose to break the chunk up by delimiters ("\r\n" by default, but you can choose any delimiter) or just have every chunk be the same size.
- By default, the plugin will infer the line terminator of a file, so you don't need to do anything.
- A nice form for moving between chunks.
- A form for finding and replacing text in the file.
- JSON files can be broken into chunks that are all syntactically valid JSON.
- Each chunk of the file can be written to a separate file, optionally in a new folder.
molsonkiko12- LargeFile.vim
LargeFile.vim is a plugin that disables certain features of Vim to improve editing speed for large files, as Vim's background processes can be time-consuming.
13- Apache Spark
Apache Spark is an open-source distributed computing system that is designed for big data processing and analytics. It provides an interface for programming clusters with implicit data parallelism and fault tolerance.
Apache Spark has the capability to read and process large text files. It can efficiently handle large datasets by distributing the workload across a cluster of machines. Spark's core abstraction, the Resilient Distributed Dataset (RDD), allows for parallel processing and fault tolerance, making it suitable for processing large-scale data, including large text files.
14- XSV
If you are looking to efficiently read large CSV files, we confidently recommend utilizing this powerful open-source command-line tool XSV. This impressive tool is expertly crafted using the robust Rust programming language.
BurntSushi15- Reading large Excel Files
This is a sample project that shows how to read large excel files returning the row content using observer pattern (using PropertyChangeListener).
williamcrocha16- sxl (Python)
This is a free and open-source Python library that enables you to read large Excel files easily.
ktr17- xlsx-reader
Python3 library optimised for reading very large Excel XLSX files, including those with hundreds of columns as well as rows.
Final Note
Reading large text files is crucial for various data-related tasks, including analysis, cleaning, machine learning, and information retrieval. With the availability of specialized tools and libraries, handling large text files has become more efficient, enabling organizations to extract valuable insights from massive amounts of data.
Hazem