Vibe Coding from 30,000 Feet: Introducing Gemma Chat

What if you could "vibe code" from a cabin with no cell signal, an airplane seat, or a workspace with zero Wi-Fi? Better yet, what if you could do it without ever sending a single line of your proprietary code to someone else's server?
Meet Gemma Chat, an open-source Electron app that brings the power of local-first, offline development to your Mac. Powered by Google’s Gemma 4 and optimized for Apple Silicon via the MLX framework, this isn't just a chatbot—it’s a fully offline coding agent that works wherever you are.
No Cloud. No Keys. No Wi-Fi.
The traditional "Vibe Coding" movement has largely been tied to massive cloud-based models. Gemma Chat flips the script. By running a compact, high-performance ~3 GB model natively on your machine, you get a powerful assistant that requires zero API keys and zero internet connection after the initial setup.
The Workflow: From Thought to Preview
Gemma Chat is designed for rapid, iterative building. You describe what you want—be it a "retro calculator" or a "modern landing page for a coffee shop"—and the agent gets to work.
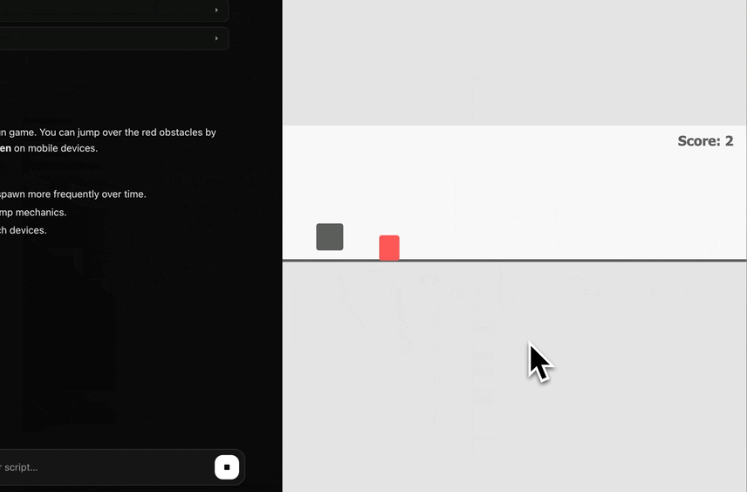
- Build Mode: Watch as the agent writes HTML, CSS, and JavaScript character-by-character. It handles multi-file projects in a sandboxed workspace.
- Live Preview: The built-in canvas updates in real-time as the model types, allowing you to see your vision come to life instantly.
- Iterate Locally: Need a different color scheme or a new feature? Just ask. The model edits the files and the preview refreshes without a single packet leaving your laptop.
More Than Just Code
While the coding agent is the star of the show, Gemma Chat also includes a versatile Chat Mode. This conversational AI supports native tool use, including:
- Local bash execution
- A built-in calculator
- URL fetching and web search (when you do decide to reconnect)
Why Local-First Matters
For developers focused on Agentic Engineering, Gemma Chat represents a major milestone in privacy and reliability. It proves that small, open models are now capable enough to handle implementation tasks, leaving the human developer to focus on architecture and quality.
Whether you are a security-conscious professional or a developer who finds their best "vibe" far away from the distractions of the internet, Gemma Chat is your new essential tool. Your code, your prompts, and your conversations stay exactly where they belong: on your machine.
Core Capabilities
- Offline Development: After an initial model download, the entire coding experience—including multi-file project generation and previews—runs without Wi-Fi.
- Local-First Privacy: No API keys or cloud services are required; all prompts and source code remain entirely local.
- Build Mode: A dedicated coding agent with a sandboxed workspace and a live preview canvas that updates in real-time as the model types.
- Chat Mode: A standard conversational AI interface that supports advanced tool use like web searching, URL fetching, and bash commands.
Technical Features
- MLX Integration: Uses Apple's MLX-LM framework to optimize performance on Apple Silicon.
- Character-by-Character Live Preview: Streams file content to disk every ~450ms, allowing you to watch the application build itself in an iframe.
- XML Action Parsing: Uses an XML-based tool protocol instead of JSON, which allows small models to handle multi-file writes and bash commands more reliably.
- Model Hot-Swapping: Allows users to switch between four different Gemma 4 variants on the fly based on their RAM and reasoning needs.
- Voice Input: Includes local speech-to-text functionality powered by an in-browser Whisper model.
User Experience & Setup
- Zero Configuration: Automatically provisions a local Python virtual environment and the MLX runtime upon the first launch.
- Distributable Packaging: Capable of producing a signed
.dmgfile for easy sharing between macOS users. - Workspace Sandbox: Each conversation is isolated within its own local filesystem and static file server for secure project management.
Available Local Models
| Model Variant | Size | Best For |
| Gemma 4 E2B | ~1.5 GB | Fast Q&A and simple tasks |
| Gemma 4 E4B | ~3 GB | Recommended: Balance of speed and capability |
| Gemma 4 27B MoE | ~8 GB | Strong reasoning (requires 16 GB+ RAM) |
| Gemma 4 31B | ~18 GB | Maximum quality (requires 32 GB+ RAM) |
It runs natively on Apple Silicon using the MLX framework, ensuring your code and conversations stay on your machine.
License
MIT License
Downloads